Methods
Data
The Early Endovenous Ablation in Venous Ulceration (EVRA) randomised clinical trial evaluated the cost-effectiveness of early versus deferred endovenous ablation to treat venous leg ulcers. The trial methods and patients are described elsewhere (4). Briefly, resource use items in hospital, primary and community care and medications related to the treatment of venous ulceration, adverse events or complications were collected by case note review and questionnaires completed at baseline and monthly thereafter up to one year, plus one further telephone follow up between October 2018 and March 2019.
The baseline covariates included in all the estimation models were: TREAT is treatment randomised (“early” coded as 1 or “delayed” coded as zero). The variable is the time variable (coded as a set of categorical (dummy or factor) variables) representing the week after randomisation at which data are observed, from t=0 (baseline) to t=16 (week 260). SIZE, AGE and DURATION are the ulcer size(cm2), subject’s age (years) and length of time with ulcer (years), respectively, measured at baseline and centred at the means. SITE was coded as a factor variable.
Each item of resource use was multiplied by UK unit costs obtained from published literature, NHS reference costs, and manufacturers’ list prices to calculate overall costs within each of these categories for each patient (4). The costs for each individual over their follow-up (from randomization to date of censoring for that individual) were assigned or apportioned into discrete time periods, that corresponded to 12 monthly periods during the first year (as follow-ups were monthly) and then yearly periods thereafter. This allowed discounting to be applied (3.5% per year), and facilitated analysis using the MI and mixed model in long format (see below).
EQ-5D-5L was collected at baseline, 6 weeks, 6 months, 12 months, plus one further telephone follow up between October 2018 and March 2019, and a utility index was calculated at each time point using a published tariff (13).
Patients who died during the study were assigned zero costs and HRQOL thereafter. Code and example data are available in the Supplementary data, http://dx.doi.org/10.17632/j8fmdwd4jp.5.
Missing data
Due to rigorous follow-up procedures, there were very few withdrawals or dropouts from the study. Nevertheless, data are incomplete in this study for two reasons. First, recruitment of the 450 patients into the clinical study across the 20 vascular centres took place between October 2013 and September 2016. The study finalised on March 2019. This “staggered” recruitment into the trial meant that patients had a minimum of 1 years of follow-up and a maximum of 5.5 years (median 3 years).
Figure 1 about here (censoring pattern)
Second, all patients had regular and periodically scheduled follow-up during the first year after recruitment, but to keep the cost of the research study low, only one further telephone follow-up per patient was conducted. This took place between October 2018 and March 2019. Figure 1 shows how this study design influences the missing data pattern. A patient recruited in 2014 will have complete follow-up during the first year, missing data at years 2, 3 and 4, and one follow-up at 5 years (patient A). A patient recruited in 2015 will have complete follow-up during the first year, missing data at years 2 and 3, one follow-up at year 4, and missing data for year 5. A patient recruited in 2016 (patient C) will have complete follow-up during the first year, missing data at year 2, one follow-up at year 3, and missing data for years 4 and 5. This mainly affected collection of EQ-5D, because in the absence of telephone questionnaire data, most types of resource use and clinical outcomes could be obtained from case-notes.
The pattern of missingness was examined using descriptive statistics and via the linear logistic model (Equation 1). This can distinguish MAR from Missing Completely At Random (MAR), although cannot rule out the possibility that data are missing not at random (MNAR) (1).
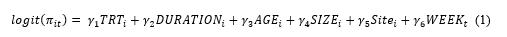
where π denotes the probability that an observation is missing in individual i at time t.
Analytic approaches
Cost-effectiveness analysis was conducted using five analytic approaches to handle missing data: CCA, BPA, MILR, MIPMM and RMM. CCA and BPA are implemented using aggregate data, using the typology of Gabrio, A. et al. (5), while MI and RMM are implemented using disaggregated (longitudinal) data. Statistical efficiency of the MIPMM and MILR approaches were assessed by , where FMI is the fraction of missing information and M is the number of imputed datasets. All approaches used standard statistical software (STATA or R). Further details are given in the Supplementary materials online. Table 1 summarises the approaches.
Table 1 (summary of the approaches) about here
Ethics and Consent
The trial was approved by the South West–Central Bristol Research Ethics Committee, and trial oversight was provided by an independent trial steering committee and an independent data and safety monitoring committee. Written informed consent was obtained from all participants. Details of the trial design and implementation are provided in the published protocol of the EVRA study (4). The study was conducted in accordance with the recommendations for physicians involved in research on human subjects adopted by the 18th World Medical Assembly, Helsinki 1964 and later revisions.