3 Experimental Setup
This section describes the components of the experimental setup used in this work for the comparative analysis and performance evaluation of different preprocessing strategies (Fig. 1).
3.1 Datasets
This work considers two publicly available benchmark retinal image datasets with sufficient number images with image-level annotations for DR severity grades.
3.1.1 Kaggle EyePACS dataset:
Kaggle EyePACS dataset20 consists of total 88,702 images with 5 DR stages labeled, with 35,126 images in the train set and 53,576 images in the test set. The distribution of classes in the dataset is depicted in Table 1, it is apparent that the dataset suffers from class imbalance.
3.1.2 APTOS Dataset:
APTOS dataset10 is the most recent dataset on Indian cases with five-class DR grading annotations. It consists of 3662 training images and 1928 test images with varying resolutions from maximum resolution of 3216x2136 to minimum resolution of 640x480. The details of the dataset is depicted in Table 1, it also suffers from class imbalance.
|
Class |
DR Stage |
Kaggle EyePACS dataset20 |
APTOS dataset10 |
||
|---|---|---|---|---|---|
|
#images |
Percent. |
#images |
Percent. |
||
|
0 |
No DR |
25810 |
73.48% |
1805 |
49.29% |
|
1 |
Mild DR |
2443 |
6.96% |
999 |
27.28% |
|
2 |
Moderate DR |
5292 |
15.07% |
370 |
10.10% |
|
3 |
Severe DR |
873 |
2.48% |
295 |
8.05% |
|
4 |
Proliferative DR |
708 |
2.01% |
193 |
5.27% |
Most the contributions in the field of DR-grading have been trained and evaluated on Kaggle EyePACS dataset. Therefore, we use the Kaggle EyePACS dataset to train our model and APTOS dataset to test the performance. This helps to validate the cross-dataset robustness of the preprocessing strategies.
3.2 Deep Convolutional Neural Network (DCNN)
The reviewed works indicate that, DCNN is the most popular choice among the researchers for DR detection tasks, as they are specially designed to efficiently learn and extract meaningful features from the images. Filters or kernels in the convolution layers employ convolution operations to encode local spatial information to detect significant patterns and objects within the image. The lower level convolutional layers learn to detect edges and structures by aligning the filters as edge and blob detectors. On the other hand, deeper convolutional layers learn to detect more and more abstract structures and objects, which are scale, rotation and translation invariance, by aligning themselves as high-end feature extractors or image descriptors. It is observed from the reviewed literatures, that VGG-Net, ResNet9 and their variants have been extensively adopted by the researchers and observed reasonably good performances in all three types of DR classification tasks. Other important models which are successfully used are GoogLeNet (Inception V1), Incetion-V3, Inception-ResNet (Inception V4), and Alex-Net. It is found that ResNet and its variants have outperformed other state-of-art CNNs, in both DR screening and DR-gradation tasks. The ResNet model apparently has the better ability to learn the most expressive and discriminative features from the retinal images, which probably contributed in better classification results. This is the rationale behind selecting ResNet as the baseline classification model for the experimental setup. The building blocks for learning of the residual function F in ResNet 34 and ResNet 50/101/152 are depicted in Fig. 3(a) and 3(b), respectively. Taking into account the promising performance of the shallower models like VGG- Net variants and AlexNet in DR-grading and in DR-screening, we select a moderately deep ResNet-50 CNN as the baseline DCNN architecture for the classification tasks.
3.3 Evaluation Metrics:
In a binary classification settings, the evaluation metrics are based on four basic measurements, namely true positive (TP), true negative (TN), false positive (FP) and false negative (FN). For measuring the performance of classification tasks like DR-grading, sensitivity (SN) or recall (RE), specificity (SP), accuracy (ACC), precision (PR), Area under the Receiver Operating Characteristic curve (AUC-ROC) and quadratic weighted kappa (κ) score are commonly used. Quadratic weighted kappa (κ) score is an effective weighted measure, especially in assessing classification accuracy in multiclass classification like DR-grading where datasets suffer from class imbalance problems. Eqs. (1), (2) and (3) depicts the three metrics – Accuracy, Quadratic weighted kappa (κ) score and AUC-ROC used in this work to compare performances of different preprocessing approaches.
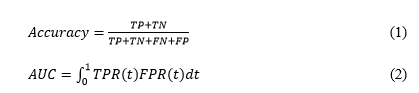
Where, t = probability threshold, and TPR(t) is True Positive rate and FPR(t) is the False Positive rate.

Where, N = number of classes, Oij = elements of a N ⋅ N histogram matrix of observed ratings (O) and corresponds to the number of adoption records that have a rating of i (actual) and received a predicted rating j, wij = elements of a N ⋅ N weights matrix (w) calculated based on the difference between actual and predicted rating scores, Eij = elements of a N ⋅ N histogram expected ratings (E).