Setting:
This study was conducted in 11 counties of the province of Golestan in Iran in 2018 (Figure 1). It covers an area of 20,367 with a population of 1,868,819 people. The study area was shown in figure 1, and the points represent 69 milling factories included in this research.
Data sources:
We used two different data sources; cancer registry to extract colon cancer events and calculate age-standardized rate (ASR) of colon cancer. The second data was the heavy metals in rice samples analyzed by laboratory including Zink (Zn), Cadmium (Cd), Lead (Pb), Copper (Cu), Nickel (Ni), Cobalt (Co), and Selenium (Se). We used the ASR of colon cancer as the dependent variable for statistical modelling.
Sampling: The sample size was estimated based on a study that was conducted by Zazouli et al. (2008) [23] in cultured rice in the province of Mazandaran, which is similar to Golestan climate. As lead conformed a large proportion of heavy metals, the sample size was calculated based on lead. Confidence interval level (α = 0.05) and error rate (d) were assumed .05%, using formula 1.

where z is value of normal variable with confidence level of , is the standard deviation of the amount of lead, and d is error rate.
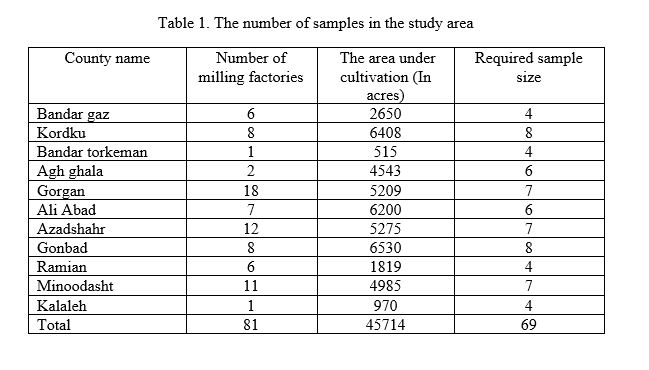
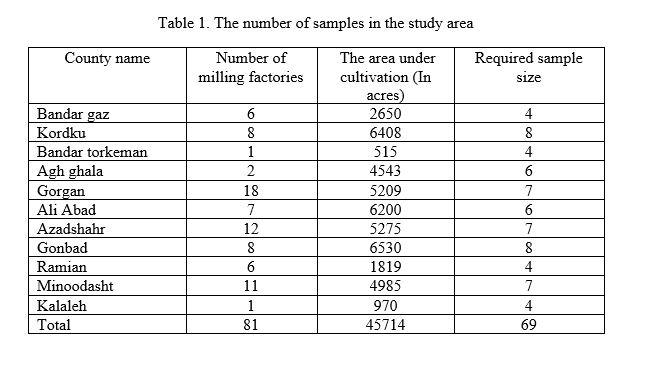
The required sample size was determined 62. Considering adequate allocation of the area under cultivation, for some counties sample size was estimated 1 or 2, which was not interpretable. As a result, at least 4 cases were considered for each county and ultimately, a total of 69 samples were investigated in this study. The number of samples for every county in the study area is shown in Table 1.
Considering that after harvest, rice shawl will be delivered to milling factories to subsequent operations, samples were drawn from milling factories in each county. In cases that the number of milling factory was more than the number of samples, one sample was obtained from each factory, and then samples were taken from a mixture. The mixture was prepared from samples taken from each factory by mixing them together and then we took a 0.5 kg sample from the mixture for investigation. The plastic bags were transported to the environmental chemistry laboratory of the school of public health and kept in the refrigerator till analyses to be conducted. In investigation step, the concentration of seven heavy metals in samples was measured including Zink (Zn), Cadmium (Cd), Lead (Pb), Copper (Cu), Nickel (Ni), Cobalt (Co), and Selenium (Se).
Spatial Analysis:
Interpolation:
Kriging is an interpolation algorithm that predicts the unobserved values based on known points values [24]. In this study, the Kriging method was used to spatially interpolate the amount of heavy metals in the study area, considering 12 near points. Kriging is most appropriate when there is a spatially correlated distance or directional bias in the data. Its result is a raster dataset in which every pixel shows the amount of one of the heavy metals in that particular area estimated by 12 near sampled points.
We converted the kriging results into vector polygon layers by creating a point layer of pixels and then spatially joined the points to the digital layer of Golestan counties using ArcGIS 10.1. The average of each heavy metal values was calculated for each county polygon.
Exploratory Regression mining:
we used the exploratory regression analysis approach to develop several regression models. Explanatory variables were heavy metals, and the dependent variable was ASR of men and women colon cancer. We used ArcGIS 10.5 to conduct the exploratory regression analyses. This tool runs many OLS models using all possible combinations for a list of independent variables and evaluates which model better fits. The six items addressed in assessing an appropriate regression model are [25] :
1. Expected sign for each coefficient:
The sign of each coefficient should be consistent with the scientific literature. For example, in recent literature lead has had a positive correlation with cancer occurrence and we expect to find a consistent result in our study.
2. Lack of redundancy among dependent variables:
Variance inflation factor (VIF) should be smaller than about 7.5 for any variables otherwise collinearity will be between some exposure variables.
3. Significance of coefficients:
Probability and Robust Probability in the result should be checked to assess if coefficients are statistically significant.
4. Normal distribution of residuals:
For this purpose, Jarque-Bera test should not be statistically significant and sum of residuals should be zero with a SD of 1.
5. Strong adjusted R-squared value:
The adjusted R-square value should be at least more than 0.5.
6. Lack of spatial autocorrelation among OLS residuals:
Global Moran’s index can be used to measure spatial autocorrelation.
{kind=link}
{kind=link}