Data
All data used was accessed and analysed through the System of Social Statistical Datasets (SSD) of Statistics Netherlands. The SSD provides access to multiple administrative data sources, the ability to link pseudo-anonymised data at the individual level, and serves as a Trusted Third Party (TTP). Analyses took place in a secured environment and results can only be exported after control by SSD for privacy and security issues.[17] Dutch law allows the use of electronic health records for research purposes under strict conditions. According to this legislation, neither obtaining informed consent from patients nor approval by a medical ethics committee is obligatory for this type of observational studies containing no directly identifiable data (Dutch Civil Law, Article 7:458).
The population consisted of all those living in the Netherlands on December 31st 2012. Of the 16,779,412 persons recorded, for 16,777,888 persons (99.9%) data was available on date of birth, gender, marital status, municipality, ethnicity, being 1st or 2nd generation immigrant, percentile group of wealth, source of income, percentile group of household income and household composition.
Individual data on medication use were obtained from Medicijntab [18], ‘containing data on persons to whom medicines were dispensed and reimbursed under the statutory basic medical insurance in the year concerned.’ While all individuals have basic insurance, medications reimbursed differently or sold over the counter are not included. It was assumed that individuals with no record of a certain ATC3 code did not use this medication in the year of interest.
Diagnosis data was available from two sources, a primary care database and hospital records. When a person was registered in one of the practices participating in the primary care database, the person was included in what we will refer to as the ‘training set’. All Dutch inhabitants are registered in a primary care practice for insurance purposes. The NIVEL primary care database [21] comprises approximately 10% of the Dutch population, with most practices entering during 2002–2006. Diagnostic codes were given by general practitioners in ICPC-1 code [19], and covered all individuals registered to a GP practice as of date of entry of either the GP into the registry, or the individual into the GP practice.
Clinical and day admissions to hospitals were available from the National Medical Registry [‘Landelijke Medische Registratie’(LMR)] [20] from 2002–2012. For 2012 it was estimated that around 25% of admissions were missed by Statistics Netherlands, while there were fewer missing cases in the previous years [20]. Most hospitals reported in ICD9, while in 2012 several hospitals reported in ICD10.
If a person had been diagnosed with one of the codes available in Table 1, in either the hospital data (primary and secondary diagnosis) or the primary care data, we considered the person to have the disease/diagnosis category indicated. For stroke and myocardial infarction, having experienced the event in the period covered by the datasets was considered as a chronic disorder for the current study. When neither the hospital records, nor the GP registry indicated a diagnosis, the individual was considered disease free.
About 85% of patients in this database could be uniquely linked in the SSD environment to the full set of socio-demographic variables, resulting in a training set of 707,021 individuals, with full diagnostic information being present, as well as complete information on covariates.
Table 1
ICD10, ICD9 and ICPC codes [19] per disease
| Disease | ICD10 | ICD9 | ICPC-1 |
| Coronary Heart Disease | I20 – I25 | 410–414 | K74-K76 |
| Stroke | I60 – I69 | 430–434, 436–438 | K90 |
| Diabetes | E10 – E14 | 250, 648 | T90 |
| COPD | J40 – J44 | 490–492, 496 | R91,R95 |
| |
Table 2 shows the characteristics of the training set compared to the total Dutch population. Differences are very small, with a slightly elderly population, and slightly more pensions as source of income in the training set. The first and third quartiles are also similar for age, wealth- and income percentile.
Table 2
Descriptive statistics in percentages
| Variable | Training set | Dutch Population |
| Mean Age | 40.6 | 40.3 |
| Mean Wealth Percentile | 50.3 | 50.5 |
| Mean Income Percentile | 60.7 | 59.9 |
| Percentage Females | 51.1 | 50.5 |
| Marital Status | | |
| Unmarried | 46.5 | 47.0 |
| Divorced | 7.3 | 7.1 |
| Widowed | 5.4 | 5.2 |
| Married | 40.8 | 40.7 |
| Source of Income | | |
| Labor | 57.2 | 57.1 |
| Owned company | 14.8 | 14.7 |
| Wealth | 0.4 | 0.4 |
| Social benefits | 8.2 | 8.1 |
| Pension | 18.3 | 17.8 |
| Study Financing | 0.6 | 0.8 |
| Other | 0.1 | 0.1 |
| No Income | 0.4 | 1.0 |
| Ethnic Group | | |
| Moroccan | 2.0 | 2.2 |
| Turkish | 2.2 | 2.4 |
| Surinam | 2.1 | 2.1 |
| Netherlands Antilles and Aruba | 0.9 | 0.9 |
| Native | 80.2 | 78.9 |
| Other western | 4.0 | 4.2 |
| Other non-western | 8.5 | 9.4 |
| Immigrant generation | | |
| Native | 80.2 | 78.9 |
| 1st generation | 9.3 | 10.7 |
| 2nd generation | 10.5 | 10.4 |
| Type of household | | |
| 1 person | 15.8 | 16.5 |
| Married couple with children | 39.0 | 39.2 |
| Married couple without children | 20.0 | 19.8 |
| Non-married couple with children | 9.1 | 8.3 |
| Non-married couple without children | 6.2 | 6.3 |
| 1 parent with children | 8.1 | 7.9 |
| Institutional | 1.2 | 1.4 |
| Other | 0.5 | 1.4 |
| Source of Income | | |
| Labor | 57.2 | 57.1 |
| Owned company | 14.8 | 14.7 |
| Wealth | 0.4 | 0.4 |
| Social benefits | 8.2 | 8.1 |
| Pension | 18.3 | 17.8 |
| Study Financing | 0.6 | 0.8 |
| Other | 0.1 | 0.1 |
| No Income | 0.4 | 1.0 |
Data analysis
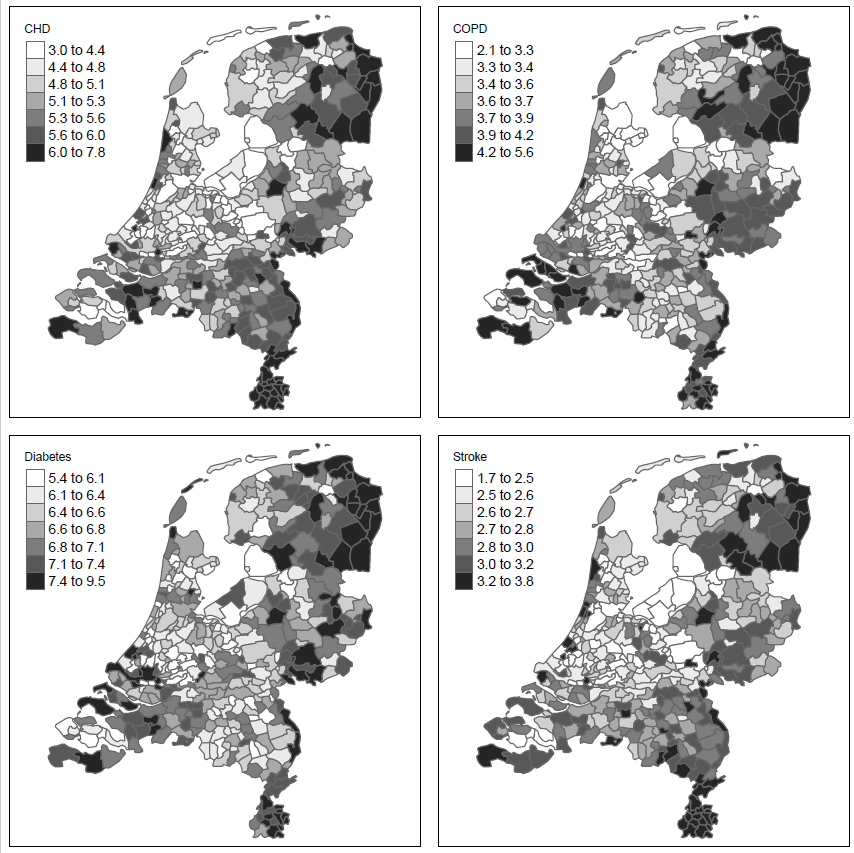
First, we estimated disease probabilities on the individual level. Then, we aggregated these probabilities into prevalence at the municipality level. All analyses were done separately for all diseases.
For our prediction model, next to ATC3 medication codes, a range of socio-economic variables was available as potential predictors. Table 2 lists the variables included and their factor levels where appropriate. Adding all interaction terms with age and age2, this amounted to 699 potential predictors. Percentile scores for income and wealth were added next to their second and third degree polynomials. Three models were distinguished and estimated separately for each disease: The complete model with all 699 predictors, the medication only model, with 182 predictors reflecting ATC3 codes, and the socio-demographics only model with 146 predictors, excluding medication use information.
In order to reduce the number of predictors, a Least Absolute Shrinkage and Selection operator (LASSO) model, with a logit link was fitted using the R package ‘glmnet’[21], with the four diseases separately as dependent variables. The shrinkage parameter was chosen that minimizes the misclassification error based on tenfold cross-validation plus one standard error[21], or such that at least 10 predictors were included, whichever of the two included the most variables. Levels of a categorical predictor were considered as separate variables.
Finally based on the total Dutch population, for each municipality, the disease prevalence was computed as the average of the predicted individual disease probabilities.
To assess the internal validity of the resulting prevalence estimates at the municipality level, 5-fold cross validation was used for the LASSO procedure.
Based on the cross-validation, the weighted percentage error (WPE) was computed at the municipality level,

where M is the set of municipalities, 0m is the observed prevalence (percentage) for municipalities in the training set, directly based on the registry data. Pm is the estimated prevalence using either the complete, the medication only or the socio-demographics only model, and wm is the weight, computed as subpopulation size in the training set compared to the size of the training set, such that the sum of the weights is 1. For municipalities with few persons in the training set, 0m is zero for several diseases. Hence, only municipalities with more than 500 persons in the training set were included in the WPE.
Next to the unstandardized results, standardized results for age were calculated by applying weights to each individual, before averaging to the municipality level. This estimate allowed to investigate regional differences that remain after correcting for differences in the age of the population. Weights were computed by comparing the age distribution of the municipality to the total Dutch population. Five-year age categories were applied for ages 20–85, while all persons aged below 20 years of age were combined in a single category and also all persons aged 85 years and over were combined in a single category.
{kind=link}