This study has highlighted promising application of ML methodology to birth weight and new-born metabolomic screening data for improving postnatal prediction of gestation age at birth and discriminating between preterm and term new-borns. It also demonstrated ability of using LMIC data for training ML models and not needing external estimators from developed country datasets. In LMIC setting of South Asia and Sub-Saharan Africa, GA estimates from ML model were within an average of 5.8 days of ultrasound based GA. The ML estimated GA enabled discrimination between pre-term and term births AUC 93% was significantly better than regression estimated GA AUC 86%. The optimal criterion of ≤ 37 weeks providing a sensitivity of 82.3% and specificity of 94.6%.
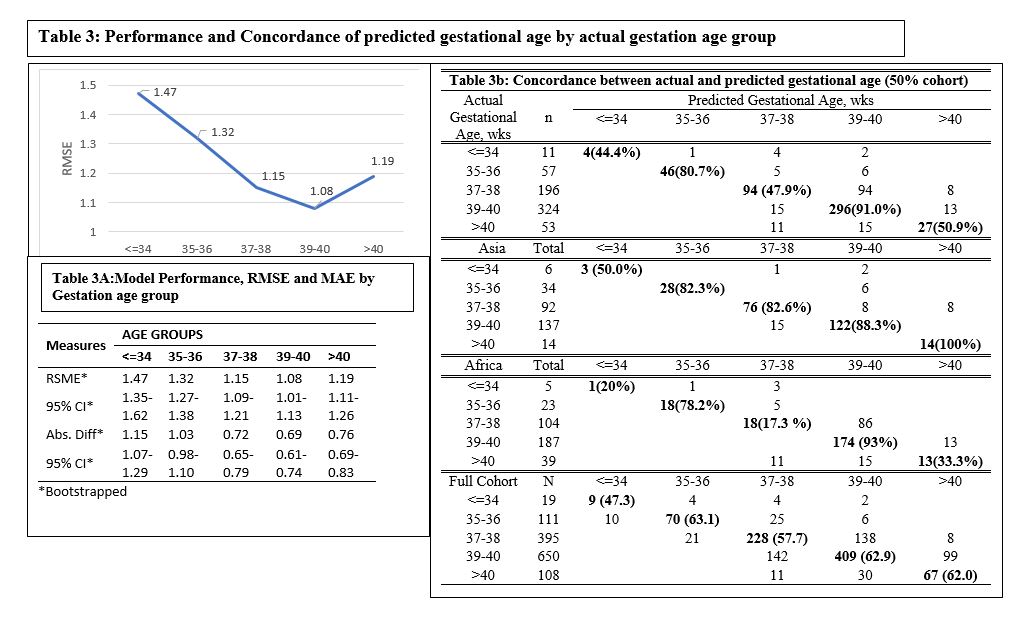
As against lower performance of previous approaches14,16−18, in estimating GA in SGA sub population, our ML model estimates were within 6.1 days of ultrasound based GA. This also reflected in the finding of a similar proportion with estimated gestation being within 1 week of the ultrasound confirmed gestation, 71.0% overall vs 71.5% in SGA subgroup. Use of data with 50% each of Asian and African data for training the models, was associated with some variation in predictive accuracy for Asia (average of 5.2 days) compared to Africa (average of 6.4 days). Using region specific data for training reduced the variation 6.1 and 6.3 days respectively yet in spite of reduced sample size of training dataset, improved the precision (Table 2). With caution of being preliminary proof of principle, these findings provide a vision for future implementations, wherein region specific training datasets may improve global application of metabolomics based data for gestational age assessment.
Our study had a number of important strengths and also some limitations which need consideration while interpreting the results. The strengths included 1) a sampling frame which utilized samples from both South Asia and East Africa, home to most of the global mortality associated with preterm and SGA births, 2) the study design was nested in a well-described population-based cohort of pregnancy with WHO coordinated and harmonized protocols and SOP, 3) Active surveillance for early pregnancy identification with added measures (menstrual calendar, pregnancy), culminating in harmonized ultrasound based gestation assessment between 8–19 weeks of gestation and 4) Sample collection, storage and shipment SOP based on pilot QC, resulting in high quality of samples. The primary limitation of this study is the participation bias against early preterm and early deaths before sample collection window. Relatively small proportion of actual births in this sub-sample limits our ability to comment on model performance in these sub-groups. Our finding of lower accuracy in pre-term ≤ 34 weeks may either reflect lack of association of the metabolites in that sub-group, a function of lack of sample in that group and/or bias introduced by selective exclusion of early deaths. Additionally we were working with the limitation of small sample size as compared to the usual sample sizes in machine learning universe. We did try to use methods appropriate to accommodating smaller sample sizes, however would not have been protected against extreme chance affecting the sample. The ability to train the model and precision of estimates is somewhat reassuring but would need confirmation.
Preterm births and SGA account for a substantial burden of mortality in first 5 years3,4. Tracking these metrics is therefore critical for advocacy, allocation of resources for surveillance, research, evaluation of preventive strategies, and care of these high-risk infants in low- and middle-income countries47,48. At the core of this is the estimation of gestational age at birth and being able to discriminate pre-term births accurately. Difference in GA at birth of a week impacts neonatal morbidity, mortality, and long-term outcomes significantly43,44. Our findings provide evidence that ML gestational dating models improve upon the currently-used postnatal gestational age estimation methods7,9,11,12,14−18. However while considering implementation of metabolic gestational dating approaches for robust population-level estimates, current challenges and future opportunities that machine learning brings to this domain need consideration. Heel prick samples for new-born screening are typically collected at least 24 hr after birth to accommodate postpartum fluctuations in analyte levels. This introduces a bias due to early deaths selectively occurring in pre-term births, further in LMIC settings most mother-infant pairs do not stay in hospital beyond 24 after delivery45. In most LMIC new-born screening is not a standard practice and will entail challenges in sample collection and processing for metabolic screening, therefore scale up needs to include rethinking about development of cord-blood-specific models restricted to analytes less susceptible to fluctuations in the postnatal environment, establishing a profile of fewer selected metabolites that are measurable in less sophisticated equipment. While rethinking and investigating low-tech variations suitable to LMIC settings, also to consider are, newer high throughput trans proteome/metabolome platforms which are now becoming affordable (i.e. Seers Nano peptide technology46). An untargeted metabolomic approach may improve our ability to estimate GA postnatally while also identifying infants at risk of a variety of conditions. Use of a broader spectrum of analytes may also help select a restrictive model for cord blood. Building on this study, use of ML methodology would positively influence development of all the above approaches, due to flexibility, ability to use regional data for ML and not requiring circling back to accumulating large datasets with new intended analyte profiles.
Summary
Towards implementing preterm birth surveillance initiatives49 ML algorithms and models applied to metabolomic gestational age dating offer an opportunity ladder to provide accurate population-level gestational age estimates in LMIC settings. Further research should focus on application of ML enabling investigation and incorporation of region-specific models, evaluating broad untargeted metabolome or more focused feasible analyte pool with ML approaches. Derivation and optimization of cord blood metabolic profiles models predicting gestational age accurately would usher a new feasibility for use of this approach in LMIC settings.



{kind=link}