3.1 Basic information of the study population
A total of 746 study subjects (118 in the ATDH group and 628 in the non-ATDH group) were included in this study. There was no statistical difference between the two groups in the proportion of gender, age, and living habits. However, the proportion of patients presenting with febrile symptoms was significantly lower in the ATDH group than in the non-ATDH group, as shown in Table 1.
3.2 Indications of clinical laboratory tests in the study population
Patients in the ATDH group had increased TBIL, indirect bilirubin, AST, ALT, alkaline phosphatase and glutamyl transferase levels and lower uric acid levels relative to those in the non-ATDH group (all p < 0.05), as shown in Table 2.
3.3 Loci typing results for the target SNPs in the study population
T allele carriers at rs3814055 of the PXR gene had a reduced relative risk of ATDH compared to C allele carriers [9]. Carriers of the rs2755237 locus C allele of the FOXO1 gene had a reduced relative risk of ATDH relative to carriers of the A allele and carriers of the T allele of the rs4435111 locus relative to carriers of the C allele. The gene frequencies of candidate SNPs for the ALAS1 gene did not differ between the two groups.
3.4. modelling of ATDH risk prediction
3.4.1 Model predictor screening
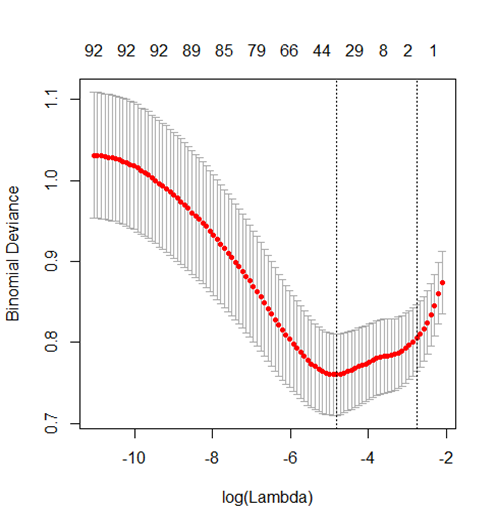
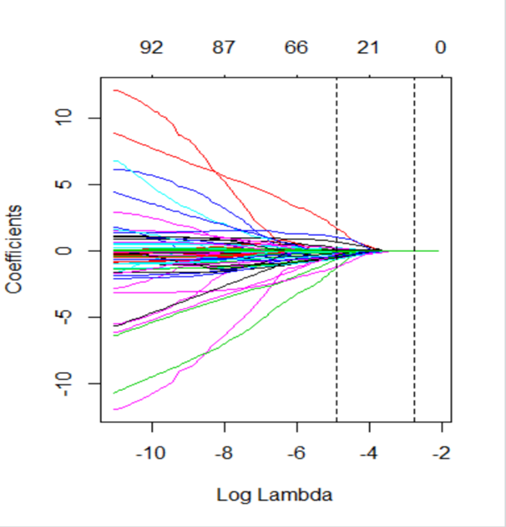
Lasso regression in the machine learning algorithm was used to screen the pre-treated 98 characteristic variables, showing that the optimal subset of non-zero coefficient variables for inclusion in the model was 36 at the minimum value of 10-fold cross-validation error λ = 0.0074528, and the coefficients of the remaining variables were reduced to zero, as shown in S 1 and 2.
3.4.2 Identification of candidate predictors using one-way logistic regression
As shown in Table 3, there are 12 candidate feature variables that are statistically different in the test set, respectively. There are 9 corresponding candidate feature variables in the validation set. The characteristic variables that were statistically different in both groups were total bile acid, glutamic aminotransferase, glutamic oxalacetic aminotransferase, and uric acid.
3.4.3 Adjustment for model confounders
There was moderate strength covariance p = 0.616 for ALT and AST and no multicollinearity between the remaining 15 candidate variables two by two with a maximum p-value of 0.26. Rs3814055 and rs4435111 had an interaction effect on the outcome variable ATDH occurrence (p = 0.001). No interactions were detected between the other 15 variables, all p > 0.05.
3.4.4 Test set model building and optimization
The 17 candidate predictors were modeled in different ways, and the screening p-values and AIC and BIC are shown in Table 4. Model 6 incorporated 5 variables with an AIC of 320.50, model 8 incorporated 9 variables with an AIC of 312.68, and model 9 incorporated 8 variables with an AIC of 312.44. Comparison of model 6, model 8 and model 9 revealed that model 6 and model 8 were different, and although model 6 incorporated fewer variables, its predictive efficacy was reduced (using STATA software's lrtest test command, p < 0.05). In contrast, there was no difference in predictive efficacy between model 8 and model 9, but model 9 incorporated fewer variables (using the lrtest test command of STATA software, p > 0.05), thus model 9 was considered the best model with the characteristics of incorporated variables as shown in Table 5.
3.4.5 Test set model predictive efficacy analysis
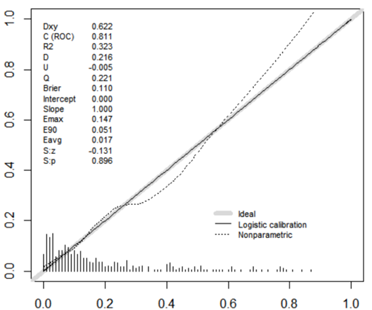
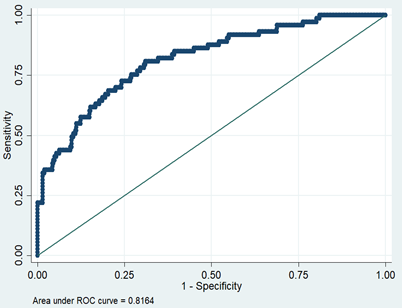
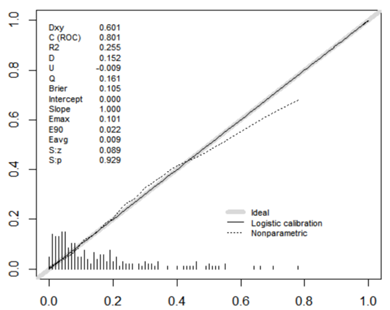
The model had a discriminant C-index of 0.816, a sensitivity of 34.25%, a specificity of 97.99%, a positive predictive value of 78.13%, and a negative predictive value of 87.69%, as shown in S 3. The model consistency test had Sp = 0.896, maximum offset Emax = 0.147 and mean offset Eave = 0.017, as shown in S 4.
3.4.6 Validation set model building and effectiveness analysis
Logistic regression models were recreated in the validation set data data summary using the regression coefficients from the test set model.
Odds (ATDH) = 1/(1 + exp(-(-3.661122 + 0.7491207 × Fever + 0.0676586 × Alb-0.0023242 × Uric + 0.1458457 × Monocyte % + 0.050343 × AST + 0.0662291 × ALT − 1.373078 × rs4435111–0.5698482 × rs3814055))).
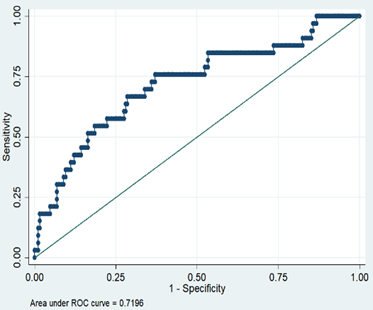
The fit of this model was consistent with the model constructed from the test set data (Hosmer-Lemeshow test p = 0.4636). Validation set the model ROC curve analysis discrimination C-index 0.7196, specificity 97.77%, negative predictive value 86.21%, sensitivity 15.15%, positive predictive value 55.56%, as shown in S 5; calibration curve validation maximum offset Emax = 0.101, mean offset Eave = 0.009, p = 0.929, as shown in S 6.
3.4.7 Building the column line graph model
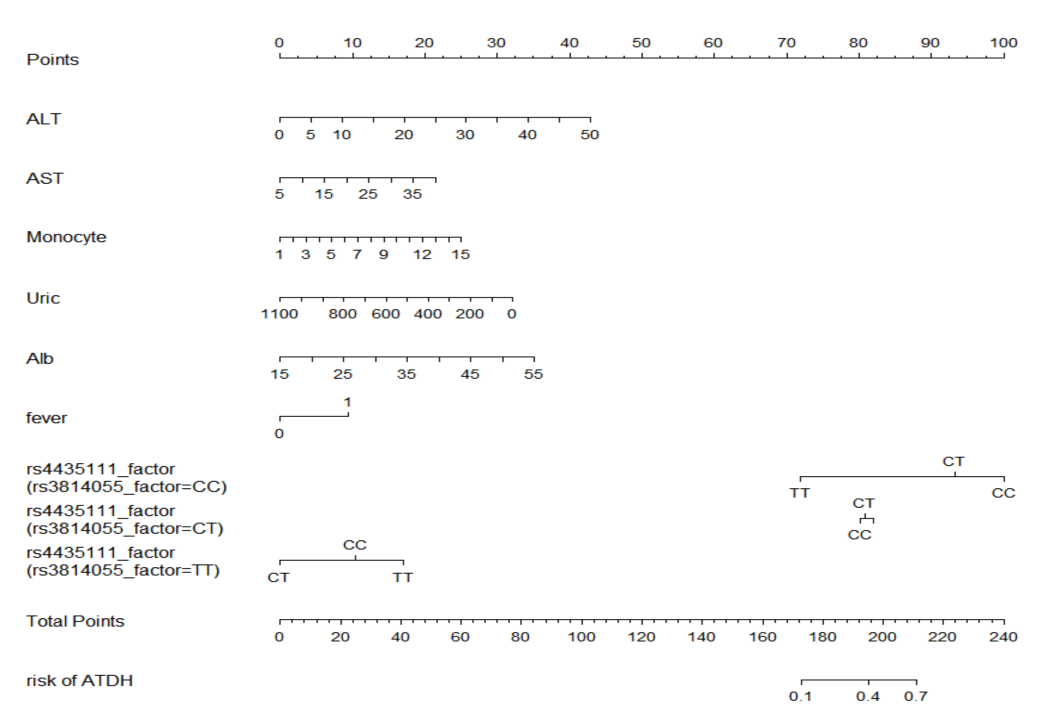
The column line graph was established according to this prediction model, and the genotypes of rs3814055 were stratified because of the interaction between rs3814055 and rs4435111. Because the different genotypes of rs3814055 and rs4435111 had non-equal predicted risk of ATDH, the different genotypes were set according to dummy variables. The column line graph model is shown in S 7, with predicted probabilities between approximately in the range of in the range of 0.1–0.7 for total integrals between 170–210.
3.4.8 DCA effects analysis of the prediction model
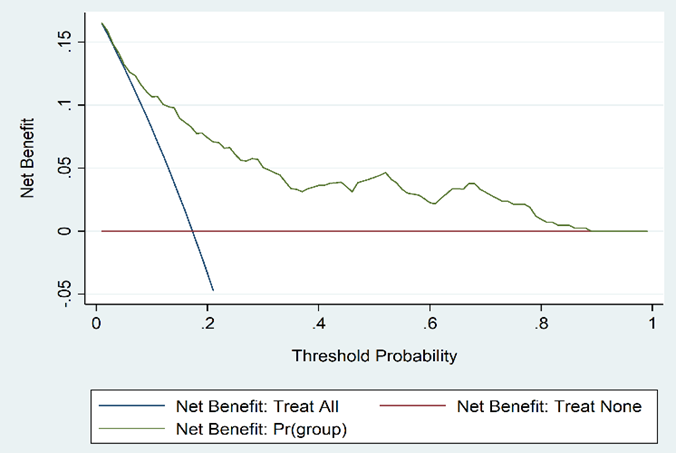
The clinical decision curve for the ATDH prediction model is shown in S 8. The model has value for clinical use when the risk threshold ranges between 0.1 and 0.8.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}