Study population
The study is a single-center, observational study focusing on 1022 inpatients receiving coronary angiography in Peking Union Medical College Hospital from January 2012 to December 2013. The patients were informed and signed informed consent about participating in a long-term follow-up research program. Patients who rejected participation or failed to offer stable contact information were excluded. Other exclusion criteria include: 1) Autoimmune disease; 2) Malignancy; 3) Current infection; 4) Asthma; 5) Dermatitis; 6) Vasculitis; 7) Abnormal liver function with alanine aminotransferase (ALT) > 3 times of upper limit; 8) Severe renal failure with estimated glomerular filtration rate (eGFR)<30mL/(min*1.73m2).
Finally, a total of 495 patients who met the enrollment principles were included in the present analyses (Figure 1).
Clinical data collection and definition
Patients’ demographic information, medication, medical history, physical and laboratory results, were extracted from the discharged medical records in the electronic medical information recording system of Peking Union Medical College Hospital. Body mass index (BMI) was calculated via equilibrium: BMI = weight (kg)/[height (m)]2. Medical history, including smoking, drinking, hypertension, dyslipidemia, and diabetes, was extracted and recorded as long as available in patients’ electronic medical records. The diagnostic criteria of these diseases were demonstrated in the supplementary method section of supplementary material.
All the patients were divided into 5 groups according to their diagnosis: 1) Cardiovascular high-risk patients (CHR): patients with <50% stenosis in the main coronary arteries did not meet the diagnostic criteria of CHD, but did in a high risk of developing CHD. Patients with >50% stenosis were diagnosed with CHD, which could be further classified to diagnosis 2), 3), 4) and 5). 2) Stable angina pectoris (SAP): patients with classical symptoms of angina yet did not meet the diagnostic criteria of unstable angina (UA). 3) UA. The angina symptoms of patients met the following criteria: prolonged anginal pain (>20 min) at rest, or newly onset angina, or destabilization of previous existing angina, or post-myocardial infarction angina. 4) Non-ST segment elevation myocardial infarction (NSTEMI). 5) ST-segment elevation myocardial infarction (STEMI). Myocardial infarction was defined as rising and/or fall of cardiac troponin above 99th percentile upper reference limit for at least one time, with at least one of the following expressions: 1) Myocardial ischemia syndrome; 2) New electrocardiography (ECG) changes indicating ischemia; 3) Pathological Q waves; 4) Imaging evidence showing the loss of new viable myocardium or newly developed segmental wall motion abnormality; 5) Identification of intracoronary thrombus via angiography or autopsy[20]. Myocardial infarction patients were further diagnosed as NSTEMI or STEMI based on the results of ECG.
Coronary angiography was performed by experienced interventional cardiologists in Peking Union Medical College Hospital. Coronary angiogram data were recorded and analyzed by two experienced cardiologists with more than ten years of experience who were blind to the study. Gensini score was used to evaluate the severity of atherosclerosis and the differential diagnosis of CHR and CHD patients.
Serum CCL17 quantification
The blood sample was collected from the radial or femoral artery after sheath insertion before coronary angiography for serum CCL17 testing. The serum was isolated by centrifugation(3000rpm,10min)and was frozen at -80℃ immediately until CCL17 measurement. Serum CCL17 level was tested via the Quantikine ELISA kit for human CCL17 (R&D Systems, Minneapolis, MN, USA) according to the manufacture’s instruction. The result was read through Labsystems Multiskan MS spectrophotometer (Thermo Labsystems Oy, Helsinki, Finland).
Follow-up and endpoint event
Upon being discharged, patients that agreed to participate in the long-term research program would receive routine telephone follow-up by trained professionals blinded to patients’ information annually. The follow-up was carried out till December 2020. Attention was paid to the incidence of major cardiovascular events (MACE). The information was further verified by corresponding medical records if necessary. Patients who failed to respond for 6 times consecutively, or changed the contact information, were defined as loss to follow-up.
The definition of MACE includes: 1) All-cause death; 2) Myocardial infarction; 3) Angina; 4) Heart Failure; 5) Ischemic cerebrovascular event; 6) Hemorrhagic cerebrovascular event 7) In-stent stenosis, which is defined as >50% stenosis in-stent during follow-up; 8) Re-percutaneous transluminal coronary intervention (PCI); 9) Re-coronary artery bypass grafting (CABG). For a single patient with multiple MACE, only the most severe MACE was recorded, and the order is: Death > Re-PCI = Re-CABG > In-stent stenosis > Myocardial infarction > Heart failure > Angina > Ischemic/Hemorrhagic cerebrovascular event.
Statistical analysis
As CCL17 was a continuous variable, we applied receiver-operating characteristic (ROC) curve analysis and the Youden Index, which is defined as sensitivity + specificity – 1, to divide the CCL17 into three levels by the optimal cutoff values of the curves. For statistic description of patients’ baseline characteristics in each level, normally distributed continuous variables were expressed by mean ± standard deviation, while skewed distributed variables were expressed by median (interquartile ranges, IQR). Categorical variables were expressed by number and percentage.
ANOVA, LSD, Chi-square, Wilcoxon rank tests, and Kruskal-Wallis H tests were applied for univariate statistical inference. The Kaplan-Meier survival analyses were performed to evaluate the incidence rate of MACE in groups of different CCL17 levels and discrepancies between groups were evaluated by the log-rank test.
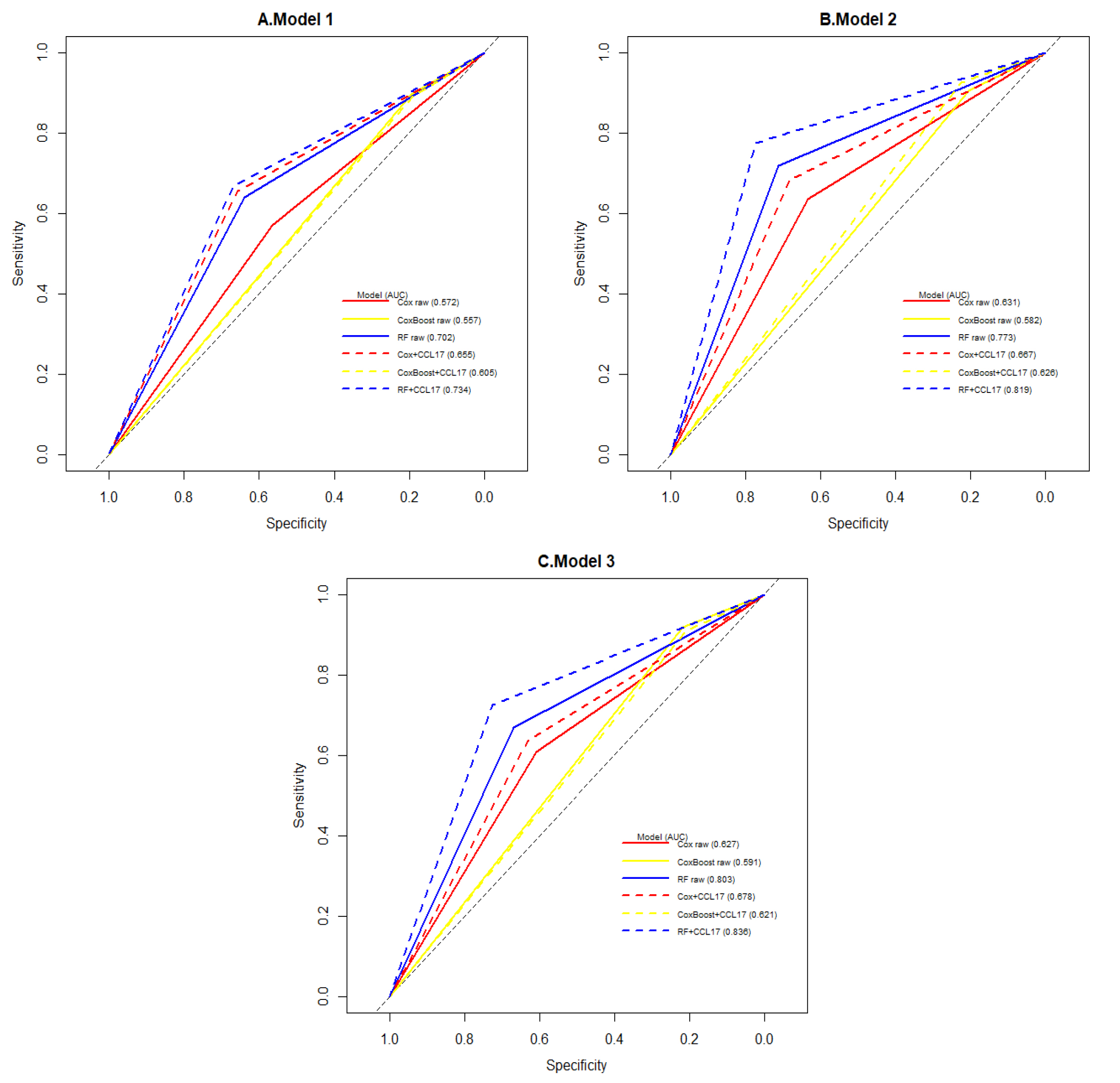
The predictive value of variables for MACE was evaluated through the univariate survival tests (Log-rank test and Cox proportional hazards analyses). In multivariate Cox proportional hazards regression models, three models were established to evaluate the predictive value of CCL17 for MACE, among which the confounders were selected based on statistical significance in univariate analysis and clinical importance. Additionally, to avoid multicollinearity in each model, not all variables with statistical significance were adjusted in all models while listed the details of confounders as follows. Model 1 adjusted for clinical demographics known as traditional risk factors for CHD: Age + Sex + BMI. Based on model 1, model 2 adjusted for additional disease risk factors: Age + Sex + BMI + Diabetes + Hypertension + Number of lesion vessels. Based on model 2, model 3 adjusted for laboratory results related to MACE: Age + Sex + BMI + Diabetes + Hypertension + Number of lesion vessels + PLT (platelet) + hsCRP (high sensitivity C reactive protein) + eGFR (estimated glomerular filtration rate)+ ALT (alanine aminotransferase).
Besides, the model performance was assessed through C-index and Area under ROC curves (AUC). Data imbalance problem has existed in this cohort as the number of patients with MACE (N=116) was more than three times smaller than that of the patients without MACE (N=379). To improve the model performance, we applied the Synthetic Minority Oversampling Technique (SMOTE) for data imbalance problems and machine learning methods for further model performance extension, including Coxboost and Random Forest (RF). According to the imbalanced data, the class with more samples were identified as the majority, and vice versa. The SMOTE is an oversampling method, which synthetic samples of the minority class by oversampling each data-point by considering linear combinations of existing minority class neighbors more samples[21]. For machine learning methods we applied, the Coxboost has added the Adaboost ensemble learning to Cox survival methods by likelihood[22]. The other survival analysis method is RF which combined tree classifiers through the Bagging ensemble learning method[23]. During the model improvement process, the dataset was divided into 10 parts randomly. Seven of them were combined for model training, while the rest three were left for model testing. Recycled the model setting process 1000 times, tested the model assessment indexes through a t-test to find out whether CCL17 could improve the machine learning model performance. The significance was defined as a p-value below 0.05.
The data analysis was conducted in SPSS 25.0 (IBM corporation, Armonk, NY, USA) and R 4.0.2. with nine R packages, including survival, survminer, tableone, broom, pROC, DMwR, ROCR, CoxBoost, and randomForestSRC.
{kind=link}