As a strategy of screening literatures for data sources, our data analysts browse the contents of each journals by issues and volumes, select the required articles based on judgments of the titles and columns, obtain the PDF version of the full text, or abstracts and bibliographic information when the PDF file is unavailable. The journals involved cover the major publications of natural product deriving researches both domestic (Chinese) and international (English), 45% of them are extensive research on natural product, others are on phytochemistry, traditional chinese medicine, food industry and miscellaneous, as shown in Fig. 3. The main list of publications that NPDB covered is included in the supporting information file provided as supplemental materials .
Insert Figure 3 here.
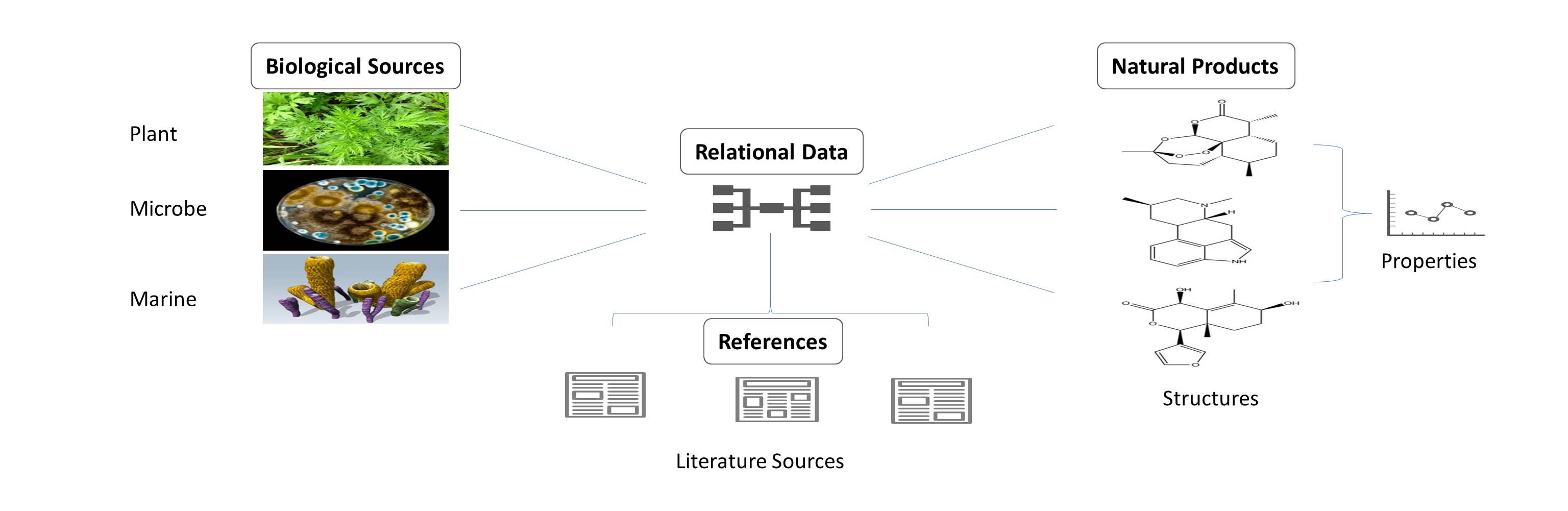
In the early stage of this work, we collected the raw data of NPDB from publications manually. Our data analysts reviewed the literatures, indexed the information of biological sources and the molecules of natural products. With the practical experience and plenty of hand-curated data, we developed a rule-based text mining system for natural product data acquisition (NPDsys), and attempted to extracted the required data information from textual description of the journal literatures automatically (Fig. 3).
Insert Figure 4 here.
The biological informations recognized in NPDsys are species names of the organisms, such as “Alternaria alternate” in Fig. 3. B,[24] and derive-parts of the organisms, such as “secondary metabolites”, “leaves”, and “aerial parts”. The chemical informations recognized in NPDsys are trivial, systematic or semi-systematic names of the natural product molecules, and the author-numbers of the molecules. The author-numbers such as “Compound A”, “Compound (1)”, are used for associating different representations of the same natural product appear in abstract, introduction, results and experimental section, or English and Chinese names of the same natural product in Chinese literatures. When the data meet the definition of “large-scale”, that information will be complementary in natural product name translation and molecular structure converting. As an exploration of chemical text-mining, the NPDsys not only get the chemical entities in literatures but also take an attempt to recognise the connections between the entities. Nevertheless, a great quantity of literatures are not available as text-mining materials, and some literatures do not provide appropriate systematic names for the “new-found” natural product molecules, lead to extra procedure of hand-drawing structures or web-searching. Therefore, the available data set in NPDB is hand-curated data at present.
The raw data had been processed properly before added into NPDB. We first assume the correctness of the primary literatures, unless there are apparent errors like typos, then backtrack on the original document when encounter abnormal data in the subsequent processing. For the same biological source from multiple literatures, we merge the data and remain the distinct natural products, and list all the references. We have similar approach for the same natural product derived from different biological sources reported by multiple literatures. When encounter multiple biological sources in one literature (For example, components of mixed species researches),[25] we label the relational data as “optional”, once other literatures reported data corroborated the natural products from one of those biological sources, the relational data will be “confirmed”.
In the process of the natural product data acquisition, the structures of the molecules are generated by “name to structure module” of ACDLabs, ChemOffice and OPSIN for computer-aided data analysing, and we use ChemDraw and Reaxys for drawing and searching the structures manually.[26–29] A machine translation tool of chemical nomenclature has been used for Chinese compound names to/from English translation.[30] We have an evaluation of the structures generated by different toolkits, scores have been made by molecular formula comparison in order to evaluate the different structures from the same compound name, and the eventual structures are standardized to MDL Molfile format. RDKit has been applied in Python for molecular properties computing in NPDB.[31, 32]
{kind=link}