3.1 Classification models
3.1.1 Diversity of dataset
We evaluated the diversity of the inhibitors in the dataset to characterize the application scope of the models. Based on the 166-bit MACCS fingerprints, we calculated the Tanimoto coefficients (Tc) among the 3097 compounds used for modeling. A smaller Tc represents better diversity. The frequency distribution of Tanimoto coefficients is shown in Fig. 2. Their average value was 0.502, and 94.41% of the compound pairs had a similarity of less than 0.7. This indicated the abundant chemical diversity of our dataset.
3.1.2 External test set distribution
To evaluate the independence of the external test set, we used a self-organizing neural network (SOM) to cluster the entire dataset (including the training set, test set, and external test set) based on the structure of the compounds, as shown in Fig. 3. In this work, SOM of 59×39 neurons was utilized based on the 166 MACCS fingerprints. The red grids contained only compounds from the training set and the test set, the green grids only contained compounds from the external validation, and the black grid contained compounds in both the training and test sets, as well as compounds in the external test set.
As a result, a total of 103 compounds were in the 67 green grids and 2542 compounds in the 596 red grids. A total of 774 compounds were in 95 black grids. 219 of them were from the external test set, and 555 were from the training sets, and test sets. That is to say, 1/3 of the external verification set had a certain novelty in structure compared to the training sets and the test sets, so the external test set can be used to verify the models.
3.1.3 Performance of classification models
In this study, MACCS fingerprints, ECFP4 fingerprints, and TT fingerprints were used to represent the inhibitors in the datasets. The MACCS fingerprints were calculated to be a 166 bits binary string, and each bit corresponds to a "predefined" structural feature. ECFP4 and TT fingerprint descriptors are circular and path-based fingerprints, respectively, computed as binary strings of 1024 bits. Due to the differences in the structures and properties of their respective representations, the performance of the classification models built by them also differs.
We adopted three random divisions and obtained three parallel training sets and test sets. Four machine learning algorithms, SVM, XGBoost, RF, and DNN were used to build models, so 12 (3×4 = 12) models were built based on each type of fingerprints. The optimal hyperparameters each model ultimately used are given in Table S2-S5 of Supplementary Material 3. Model 1A-1D were models based on MACCS fingerprints. Model 2A-2D were models based on ECFP4 fingerprints. Model 3A-3D were models based on TT fingerprints. The average performance of the models based on the three training sets and three test sets was summarized in Table 3.
Table 3
Performance of 36 classification models based on the 128 MACCS fingerprints, 750 ECFP4 fingerprints, and 370 TT fingerprints
|
Model
|
Training set/test seta
|
Algorithm
|
Training set
|
Test set
|
|
Qb
|
MCCc
|
5-CVd
|
Q
|
SEe
|
SPf
|
MCC
|
|
MACCS (128 bits)
|
|
Model 1Ag
|
2074/1023
|
SVM
|
0.957 ± 0.004
|
0.91 ± 0.006
|
0.814 ± 0.003
|
0.828 ± 0.006
|
0.812 ± 0.002
|
0.844 ± 0.013
|
0.66 ± 0.015
|
|
Model 1Bg
|
2074/1023
|
RF
|
0.955 ± 0.003
|
0.91 ± 0.006
|
0.819 ± 0.001
|
0.830 ± 0.004
|
0.821 ± 0.014
|
0.840 ± 0.016
|
0.66 ± 0.006
|
|
Model 1Cg
|
2074/1023
|
XGBoost
|
0.966 ± 0.007
|
0.93 ± 0.015
|
0.816 ± 0.000
|
0.827 ± 0.005
|
0.820 ± 0.006
|
0.835 ± 0.005
|
0.65 ± 0.012
|
|
Model 1Dg
|
2074/1023
|
DNN
|
0.970 ± 0.002
|
0.94 ± 0.000
|
0.819 ± 0.002
|
0.833 ± 0.008
|
0.823 ± 0.012
|
0.843 ± 0.003
|
0.66 ± 0.015
|
|
ECFP4 (750 bits)
|
|
Model 2Ag
|
2074/1023
|
SVM
|
0.976 ± 0.003
|
0.95 ± 0.006
|
0.848 ± 0.004
|
0.856 ± 0.002
|
0.832 ± 0.007
|
0.881 ± 0.006
|
0.71 ± 0.006
|
|
Model 2Bg
|
2074/1023
|
RF
|
0.958 ± 0.007
|
0.85 ± 0.110
|
0.834 ± 0.003
|
0.852 ± 0.005
|
0.821 ± 0.014
|
0.883 ± 0.010
|
0.71 ± 0.012
|
|
Model 2Cg
|
2074/1023
|
XGBoost
|
0.979 ± 0.014
|
0.96 ± 0.032
|
0.840 ± 0.002
|
0.855 ± 0.002
|
0.838 ± 0.005
|
0.871 ± 0.001
|
0.71 ± 0.006
|
|
Model 2Dg
|
2074/1023
|
DNN
|
0.983 ± 0.001
|
0.97 ± 0.006
|
0.842 ± 0.006
|
0.862 ± 0.003
|
0.879 ± 0.012
|
0.845 ± 0.008
|
0.72 ± 0.006
|
|
TT (370 bits)
|
|
Model 3Ag
|
2074/1023
|
SVM
|
0.953 ± 0.005
|
0.91 ± 0.010
|
0.842 ± 0.004
|
0.852 ± 0.002
|
0.830 ± 0.015
|
0.875 ± 0.011
|
0.70 ± 0.006
|
|
Model 3Bg
|
2074/1023
|
RF
|
0.963 ± 0.006
|
0.92 ± 0.015
|
0.838 ± 0.005
|
0.851 ± 0.005
|
0.830 ± 0.020
|
0.872 ± 0.019
|
0.70 ± 0.012
|
|
Model 3Cg
|
2074/1023
|
XGBoost
|
0.955 ± 0.013
|
0.91 ± 0.030
|
0.835 ± 0.004
|
0.848 ± 0.006
|
0.835 ± 0.017
|
0.861 ± 0.007
|
0.69 ± 0.012
|
|
Model 3Dg
|
2074/1023
|
DNN
|
0.936 ± 0.005
|
0.87 ± 0.010
|
0.841 ± 0.006
|
0.860 ± 0.002
|
0.888 ± 0.010
|
0.832 ± 0.011
|
0.72 ± 0.000
|
| a The number of compounds in the training set and test set; |
| b Accuracy; |
| c Matthews correlation coefficient; |
| d Average accuracy of five-fold cross-validation; |
| e Sensitivity; |
| f Specificity; |
| g Mean value and standard deviation of three parallel modeling results |
The performance of the models based on the MACCS fingerprints was summarized in Table S6 of Supplementary Material 3. Model 1A_1-1A_3 (Model 1A_1, Model 1A_2, Model 1A_3) were three models built with SVM. Model 1B_1-1B_3 were models built with RF. Model 1C_1-1C_3 were models built with XGBoost. Model 1D_1-1D_3 were models built with XGBoost. The standard deviations of the models built with the four algorithms were all small, so the longitudinal comparison between algorithms can be measured by the prediction accuracy (Q) and MCC. The performance of the 12 models built with the four algorithms was comparable indicating that these algorithms were all suitable for the datasets. The MCCs of all the models based on the MACCS fingerprints on the test set exceeded 0.64, which showed that the 12 models had a good predictive effect. Model 1D_1 built with DNN performed best with a prediction accuracy of 84.16% and MCC of 0.68 on the test set. The ROC curve of Model 1D_1 is shown in Fig S1.
The performance of the models built on the ECFP4 fingerprints is shown in Table S7 of Supplementary Material 3. The MCCs of all 12 models exceeded 0.68 on the test set. It showed that these models were superior to the models based on the MACCS fingerprints. The performance of the 12 models built with the four algorithms was also comparable. DNN models performed slightly better with an average prediction accuracy of 0.862 and an average MCC of 0.72 on the test set. The ROC curves of Model 2D_1, Model 2D_2, and Model 2D_3 are shown in Fig S2.
The performance of the models built on the TT fingerprints shown in Table S8 of Supplementary Material 3 was comparable to that of the models built on the ECFP4 fingerprints. Both of them were better than the performance of the MACCS fingerprints models. DNN models performed best among the 12 models with an average prediction accuracy of 0.860 and an average MCC of 0.72 on the test set. The ROC curves of Model 3D_1, Model 3D_2, and Model 3D_3 are shown in Fig S3.
DNN algorithm seemed to be more suitable to classify the inhibitors than the other three types of algorithms in our training sets and test sets. The sensitivity (SE) and specificity (SP) of each model were comparable among the 36 models, indicating that the models had equal recognition of highly active and weakly active inhibitors without bias.
3.1.4 Prediction of the external test set
The external test set was utilized to validate the models’ performance. The performance of models on the external test set was summarized in Table S9 of Supplementary Material 3. Table 4 showed the average performance of the 36 models on the external test set.
Table 4
Performance of 36 classification models on the external test set with 321 compounds
|
Model
|
Algorithm
|
External test set
|
|
Qa
|
SEb
|
SPc
|
MCCd
|
|
MACCS (128)
|
|
|
Model 1Ae
|
SVM
|
0.673 ± 0.078
|
0.612 ± 0.105
|
0.747 ± 0.057
|
0.36 ± 0.148
|
|
Model 1Be
|
RF
|
0.610 ± 0.090
|
0.600 ± 0.151
|
0.621 ± 0.024
|
0.22 ± 0.167
|
|
Model 1Ce
|
XGBoost
|
0.575 ± 0.078
|
0.579 ± 0.128
|
0.525 ± 0.069
|
0.15 ± 0.151
|
|
Model 1De
|
DNN
|
0.549 ± 0.029
|
0.579 ± 0.097
|
0.525 ± 0.116
|
0.10 ± 0.045
|
|
ECFP4 (750)
|
|
|
Model 2Ae
|
SVM
|
0.801 ± 0.033
|
0.780 ± 0.085
|
0.825 ± 0.059
|
0.61 ± 0.059
|
|
Model 2Be
|
RF
|
0.790 ± 0.039
|
0.803 ± 0.023
|
0.775 ± 0.064
|
0.58 ± 0.081
|
|
Model 2Ce
|
XGBoost
|
0.720 ± 0.070
|
0.678 ± 0.077
|
0.770 ± 0.063
|
0.44 ± 0.139
|
|
Model 2De
|
DNN
|
0.707 ± 0.057
|
0.779 ± 0.086
|
0.648 ± 0.065
|
0.43 ± 0.115
|
|
TT (370)
|
|
|
Model 3Ae
|
SVM
|
0.846 ± 0.066
|
0.805 ± 0.143
|
0.897 ± 0.030
|
0.71 ± 0.109
|
|
Model 3Be
|
RF
|
0.828 ± 0.018
|
0.867 ± 0.012
|
0.779 ± 0.048
|
0.65 ± 0.036
|
|
Model 3Ce
|
XGBoost
|
0.846 ± 0.021
|
0.864 ± 0.006
|
0.825 ± 0.054
|
0.69 ± 0.042
|
|
Model 3De
|
DNN
|
0.807 ± 0.073
|
0.701 ± 0.098
|
0.894 ± 0.090
|
0.62 ± 0.157
|
| a Accuracy; |
| b Sensitivity; |
| c Specificity; |
| d Matthews correlation coefficient; |
| e Mean value and standard deviation of three parallel modeling results |
We can see that the models built on the MACCS fingerprints were still suboptimal among the models built on the three fingerprints. Although the performance of the TT fingerprints models was comparable to that of the ECFP4 fingerprints models on the test set, they were significantly better on the external test set.
Interestingly, the DNN models had the best performance on the test set, but they did not perform well on the external test set. This indicated that the models built with DNN learned more features of the compounds in the training sets through training and better fitted the compounds in the training sets. The models with the best generalization ability were built with SVM, followed by RF and XGBoost.
Finally, we chose four optimal models that performed well both on the test set and the external test set, as shown in Table 5. They were all built on TT fingerprints. The ROC curves of Model 3A_1, Model 3A_3, Model 3C_2, and Model 3D_3 are shown in Fig S4.
Table 5
Performance of the four optimal models based on the test set and external test set
|
Model
|
Algorithm
|
Training set/Test seta
|
Test set
|
External test set
|
|
Qb
(%)
|
SEc
(%)
|
SPd
(%)
|
MCCe
|
Q
(%)
|
SE
(%)
|
SP
(%)
|
MCC
|
|
Model 3A_1
|
SVM
|
Training set 1/test set 1
|
85.43
|
84.66
|
86.22
|
0.71
|
90.97
|
93.75
|
87.59
|
0.82
|
|
Model 3A_3
|
SVM
|
Training set 3/test set 3
|
85.14
|
81.94
|
88.39
|
0.70
|
85.05
|
82.39
|
88.28
|
0.70
|
|
Model 3C_2
|
XGBoost
|
Training set 2/test set 2
|
84.95
|
83.50
|
86.42
|
0.70
|
85.36
|
86.36
|
84.14
|
0.70
|
|
Model 3D_3
|
DNN
|
Training set 3/test set 3
|
85.83
|
89.76
|
81.94
|
0.72
|
86.92
|
81.40
|
91.50
|
0.74
|
| a The training/test sets which are constructed by random splitting the whole dataset with seed 1, 10, 111; |
| b Accuracy; |
| c Sensitivity; |
| d Specificity; |
| e Matthews correlation coefficient |
3.1.5 Molecular fingerprints analysis
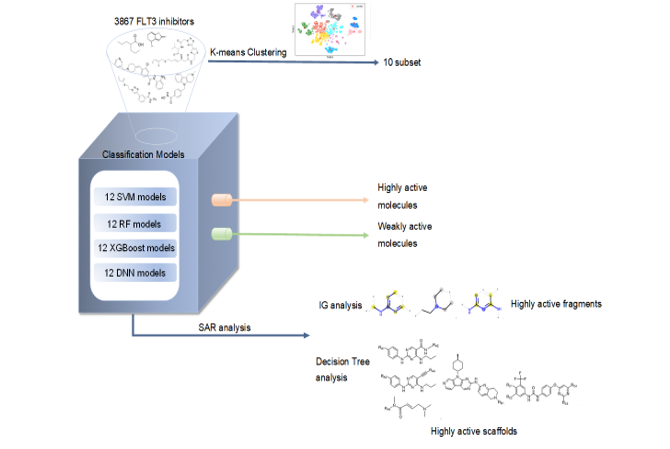
The random forest algorithm generated an information gain (IG) for each feature. To explore the structural information hidden in the models, we calculated the IG values of ECFP4 fingerprints in our RF models as shown in Fig S5 of Supplementary Material 3. The top 16 important ECFP4 keys (IG > 0.08) and the substructures they represent are shown in Table 6. The differences in the proportion of these 16 fingerprints in highly active and weakly active inhibitors were also counted. Fragments commonly appearing in highly active inhibitors were: 2-aminopyrimidine, 1-ethylpiperidine, 2,4-bis(methylamino)pyrimidine, amino-aromatic heterocycles, [(2E)-but-2-enyl]dimethylamine, but-2-enyl, and alkynyl.
In addition, each estimator in the RF represented a decision tree. We combined multiple ECFP4 fingerprints according to the dendrogram (shown in Fig. 4) of the decision tree to obtain larger scaffolds correlated with molecular biological activity. These structures are shown in Table 7.
In Subset_A, there were 384 inhibitors containing both the ECFP_459 key and ECFP_926 key, and 380 of them were highly active. The scaffolds of these inhibitors contained 5-ethynyl-2-(phenylamino)-4-(propylamino)pyrimidine moiety, N-methyl-4-(phenylamino)-2-(propylamino)benzamide moiety, and (2E)-4-(dimethylamino)-N-methylbut-2-enamide moiety. These structures also appeared in Table 6 as highly active fragments.
In Subset_B there were 102 inhibitors with the ECFP_459 key, ECFP_302 key, and without the ECFP_926 key. 93 of them were highly active inhibitors. The common structure of these molecules was 9-(4-methylcyclohexyl)-2-(5,6,7,8-tetrahydropyrido[4,3-b]pyridin-2-ylamino)pyrido[4',3':4,5]pyrrolo[2,3-d]pyrimidine moiety, just like the FLT3 inhibitor AMG-925.
In Subset_C, there were 76 inhibitors containing both the ECFP_844 key and ECFP_773 key without the ECFP_459 key. 71 of them were weakly active inhibitors. Most of these molecules had 1-{[4-(pyrimidin-4-yloxy)phenyl]amino}-N-[3-(trifluoromethyl)phenyl]methanamide moiety as their scaffold.
The substructures in Subset_A, Subset_B, and Subset_C also corresponded to the fragments in the top 16 important ECFP4 keys in Table 6. Thus, they are reliable to explore the structure-activity relationship of FLT3 inhibitors.
3.2 Clustering and analysis
To summarize the scaffolds of the reported FLT3 inhibitors, we performed a structure-based clustering. The descriptors cannot characterize macrocyclic structures, so we excluded all the macrocyclic compounds as a separate class(Subset 11 in Table 8). Each macrocyclic compound has more than 10 heavy atoms in its largest ring. Then, we used t-distributed stochastic neighbour embedding (T-SNE) [57] to reduce the 1024 ECFP4 fingerprints of the remaining 3264 inhibitors into two-dimension data as the input of K-Means [58]. As a result, the inhibitors were divided into 10 subsets. As shown in Fig. 5, the 10 subsets were clearly separated. The main scaffolds and typical ECFP4 fragments with large frequency differences between highly active inhibitors and weakly active inhibitors of each subset are shown in Table 8.
The compounds in Subset 1 were oxindole or pyrrole-2,5-dione derivatives. The oxindole or pyrrole-2,5-dione moiety was attached to pyrrolyl or binary aromatic heterocyclic moiety by cyclopropane, amino, or methylene at one end, and the other end was linked to amide or urea moiety. In addition, indene-carbazole or indole-carbazole derivatives were also in Subset 1, such as the marketed drug Midostaurin. Pyridinyl, pyrimidinyl, methylpiperazinyl, thiopheneyl, and phenyl frequently appeared in the side chain of highly active inhibitors. While 1,2,3-trimethoxybenzene moiety frequently appeared in the side chain of weakly active inhibitors.
The compounds in Subset 2 were mainly amide or urea derivatives. Amide or urea moiety was attached to aromatic heterocyclic ring moiety by aliphatic heterocyclic ring at one end and was directly linked to aromatic heterocyclic ring at the other end. The compounds containing oxazolidin-2-one moiety, oxyethyl, and phenoxy in the side chain had a higher proportion of high activity.
Among the molecules of Subset 3, the 4,5,6,7-tetrahydrobenzo[b]thiophene, pyrrolo[3,2-d]pyrimidine, and quinazoline moiety was attached to nitrogen-containing aromatic heterocyclic ring by oxygen moiety. Among them, 4,5,6,7-tetrahydrobenzo[b]thiophene derivatives were mostly weakly active inhibitors. The 1,2-dimethoxybenzene and amide moiety were mostly in weakly active inhibitors. Chlorobenzene and (trifluoromethyl)benzene moiety were mostly in highly active inhibitors.
Subset 4 contained 441 inhibitors, including 439 highly active inhibitors and 2 weakly active inhibitors. It indicated that compounds with this series of scaffolds were possibly to be highly active FLT3 inhibitors, which was similar to the conclusion obtained in Subset_A. We divided each compound in Subset 4 into three parts: left-scaffolds, linkers, and right-scaffolds. Left-scaffolds were mainly aminopyrimidine moiety, which was linked to aromatic heterocyclic ring. Linkers were mainly alkynyl or amide moieties. Right-scaffolds were mostly fat unsaturated long chains similar to the chain in FF-10101 [59]. The side chains were mainly 1-methyl-4λ2-piperazine moiety, (2-fluorophenyl)oxy, and pyridinyl.
Subset 5 comprised 9H-pyrido[4',3':4,5]pyrrolo[2,3-d]pyrimidine, benzenesulfonamide, 4,7-dihydro-3H-pyrrolo[2,3-d]pyrimidine, and 6-(1H-pyrazol-4-yl)-2H-indazole derivatives. The tricyclic structure in Subset_B also appeared in Subset 5. Chlorine-substituted compounds were mostly weakly active. Piperidinyl and pyridinyl frequently appeared in the side chain of highly active inhibitors.
Subset 6 contained amide derivatives, but their scaffolds were different from those in Subset 2. The molecular scaffolds were mainly N-(1H-pyrazole-5-yl)benzamide moiety and 2-(formylamino)-4,5,6,7-tetrahydrocyclohexa[1,2-b]thiophene-3-carboxamide moiety. The compounds containing (trifluoromethyl)benzene, 2-(2-(λ1-azanyl)ethyl)pyridine, 4-propylpiperidine, and N,4,5-trimethylisoxazol-3-amine moiety in the side chain were mostly highly active inhibitors.
The molecular scaffolds of Subset 7 were mainly 2-[(1E)-2-phenylvinyl]quinazoline-4-amine moiety, N-phenyl-1H-indazole-3-carboxamide moiety, and ternary heterocycle rings containing nitrogen or sulfur. 1-methyl-1H-pyrazole moiety, 2-(pyridin-4-yl)pyrazine moiety, 4-ethylpiperidine moiety, 2-vinylphenol moiety, and fat rings containing oxygen moiety were mostly in highly active inhibitors.
The compounds in Subset 8 were mainly urea derivatives. The urea moiety was linked to the phenyl at one end and linked to the phenyl or isoxazolyl at the other end. Weakly active scaffold in Subset_C was also appeared in Subset 8. Trifluoromethyl, 1-ethyl-4λ2-piperazine moiety, and 1-chloro-4-methylbenzene moiety frequently appeared in the side chain of highly active inhibitors, and pyrimidine derivatives with amino moiety in this subset frequently appeared in weakly active inhibitors.
The compounds in Subset 9 were mainly pyrrolo[2,3-b]pyridine derivatives. This binary ring was attached to pyridinyl or pyrimidinyl by ketone moiety or methyl. Chlorine and 1-methyl-1H-pyrazole moiety appeared in some highly active inhibitors. Pyrimidinyl and 4-(2-(methyl-azanyl)ethyl)morpholine moiety also frequently appeared in highly active inhibitors, and pyridinyl frequently appeared in weakly active inhibitors.
Subset 10 mainly comprised fused heterocyclic compounds. The two ends of the amino moiety were linked to pyrimidinyl, pyridinyl, phenyl, or other nitrogen-containing aromatic heterocycles as molecular scaffold. The compounds containing 1-methyl-1H-pyrazole moiety and trifluoroacetamide moiety in the side chain were mostly highly active inhibitors, while butyl and acrylamide moiety frequently appeared in weakly active inhibitors.
Subset 11 contained all the macrocyclic compounds. Each macrocyclic compound had more than 10 heavy atoms in its largest ring. This subset contained 154 inhibitors, including 64 highly active and 90 weakly active inhibitors. Piperidinyl, piperazinyl, and 1-(2-methoxyethyl)pyrrolidine moiety were mostly in highly active inhibitors.
{kind=link}