Data collection and study sample
Data originated from two population-based cross-sectional KORA-Age study arms: KORA-Age 1 conducted from 01.12.2008 to 06.11.2009 and KORA-Age 3 conducted from 01.02.2016 to 07.10.2016, which are follow-ups of four independent cross-sectional studies (S1 1984/5, S2 1989/90, S3 1994/5, and S4 1999- 2001). Both studies focused on the health of participants aged 65 and older in Augsburg and the two adjacent regions in Southern Germany based on questionnaires and telephone interviews. The KORA-Age study is described in detail in Peters et al. 2011 [12]. In short, 4,565 out of 5,991 eligible individuals (response rate: 76.2%) participated in the survey, and 1,920 were between 65 and 71 year-olds on 31.12.2008 (born between 1937-1943). The KORA-Age 3 survey consisted of 4,083 out of 6,051 eligible individuals (response rate: 67.5%), of whom 1,444 participants were in the same age range on 31.12.2015 (born between 1944-1950). The present analysis is based on combining these two KORA-Age study arms, which were completely independent because of the different birth years (Figure 1).
Birth phases
Based on the World War II situation in the Augsburg area, individuals were divided into five independent birth periods [Figure 1]: phase one (pre-war, January 1937-August 1939), phase two (early war, September 1939-December 1943), phase three (late war, January 1944-April 1945), phase four (famine period after the war, May 1945- Jun 1948) and phase five (after famine period and reconstruction, July 1948-Dec 1950) [10].
Outcome: Multimorbidity
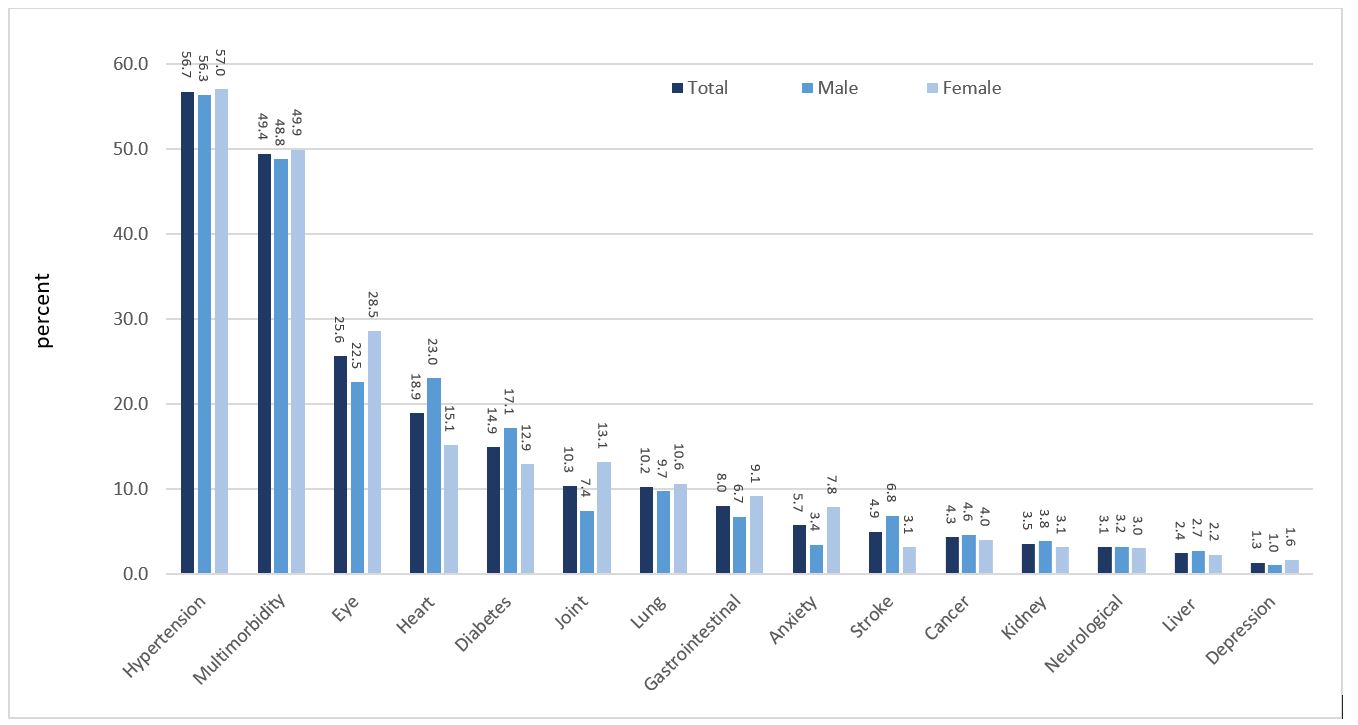
The primary outcome was MM, defined as the presence of two or more than two chronic diseases in one person simultaneously [5]. We considered fourteen major chronic diseases, including hypertension, eye disease, heart diseases, diabetes, joint disease, lung disease, gastrointestinal disease, stroke, cancer, kidney diseases, liver diseases, neurological diseases, depression, and anxiety. Hypertension, diabetes, cancer (any cancer recognized within the last three years), stroke, heart diseases (myocardial infarction and coronary artery disease) were assessed based on the questionnaire. All other diseases were identified in a telephone interview based on the Charlson Comorbidity Index [12]. Participants were asked whether they suffer from kidney, liver, lung diseases (e.g., asthma, chronic bronchitis, and emphysema), inflammatory joint problem (e.g., arthritis or rheumatism), gastrointestinal diseases (e.g., colitis, cholecystic, gastric, or ulcer), heart diseases (e.g., congestive heart failure, coronary heart failure, or angina), eye problem (e.g., cataract, retinitis pigmentosa, glaucoma, macular degeneration, diabetic retinopathy). With telephone interviews, neurological diseases were evaluated based on having diseases like epilepsy, Parkinson diseases, or sclerosis. The Geriatric Depression Scale [13] and Generalized Anxiety Disorder Scale-7 [14] were used to diagnose depression and anxiety. Persons with scores greater than ten were defined as suffering from depression or anxiety.
Explanatory variables
We considered age, sex, education level, alcohol consumption, physical activity, body mass index (BMI), smoking behavior, and cognitive status as covariates. The education level had three categories based on years of education and vocational training: low level (9 years or less), middle (10 or 11 years), and high (12 years or more). According to the categories for the body mass index (BMI) defined by the World Health Organization (WHO), we classified participants into underweight or normal weight (BMI <24.99 kg/m2), overweight (25<=BMI<=29.99), obese class I (30<= BMI < 34.99) and obese class II or III (35<= BMI) [15].
Leisure time physical activity measured from two separate questions about leisure time sports activity in winter and summer, including cycling. Possible answers were (1) > 2 hours, (2) 1–2 hours, (3) <1 hour and (4) none. Participants, who had a total score less than 5, obtained by summing the numbers (1)–(4) relating to activities in winter and summer, were classified to be “physically active” [16].
Alcohol consumption was based on self-reported alcohol intake with the following five groups: ‘‘almost every day’’, ‘‘several times a week’’, ‘‘about once a week’’, ‘‘less than once a week’’, and “never or seldom” [17]. For our analysis, we categorized the first two groups as “daily use” and the last two as “never or rare use.” Based on self-reported information, there are three categories for smoking status: never smokers, former smokers, and active smokers.
The cognitive status is identified as dementia, mildly impaired cognitive status, and normal status based on TICS-M (Telephone Interview for Cognitive Status) score, a standard instrument for assessing cognitive impairment [18].
Statistical Analysis
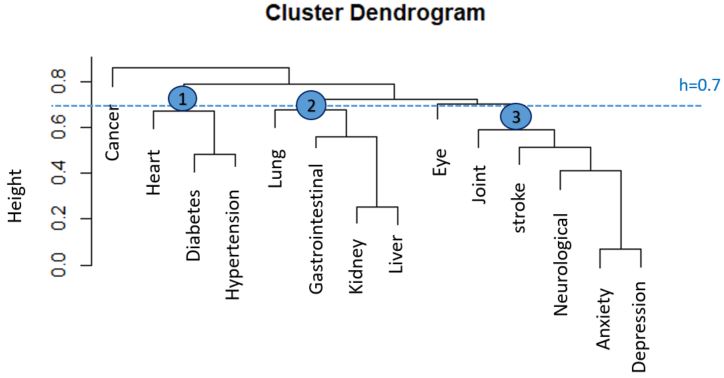
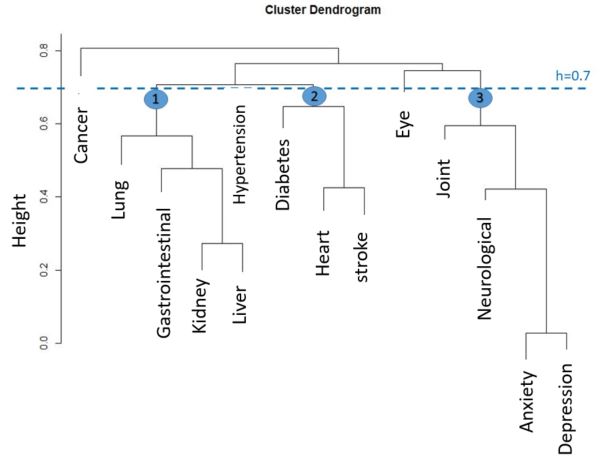
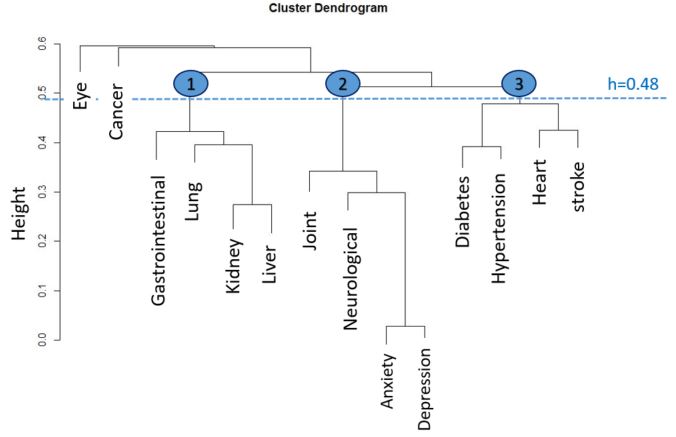
The frequency and prevalence of baseline characteristics were stratified by sex and birth phases, and the Chi-squared test was computed to check the differences. Overall, the stratified prevalence of MM and single diseases was calculated and tested by the Chi-squared test. Covariates multi-collinearity was assessed using the variance inflation factors (VIF). Associations of the birth phases and MM were estimated by odds ratios (OR) in logistic regression models with different adjustment steps for risk factors. The Modeling process started with the age variable as covariate only (model 1), then birth period only (model 2), standardized age (rescaled with mean and standard deviation) and birth period together (model 3), then sex, education, alcohol use, physical activity, BMI, smoking behavior and cognitive status were added to the final model (models 4). An agglomerative hierarchical clustering approach was carried out to identify disease clusters so that diseases in one cluster are more similar than diseases in other clusters. This bottom-up algorithm begins with each disease as an individual cluster and merges the similar clusters until remaining only one cluster based on the proximity distance matrix. The average linkage method as proximity distance and Yule Q coefficient as similarity measurement for the binary disease variables were considered. The final cluster selection was created based on the threshold (cutoff height), which corresponded to subject information, prior research, and clinical significance.
Since there is a big difference between the prevalence of hypertension and other chronic diseases, regression models and cluster analysis were performed without hypertension as a sensitivity analysis. Furthermore, the Ward and Single linkage methods as other possible determinants for the pairwise distance between the set of observations were used to determine the robustness of agglomerative hierarchical clustering [11].
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}