Genomic features of strain NCD-2
A total of 501,671,500 paired-end reads and 5,016,715 clean single reads (412-bp library; paired-ends of 75 bp) were assembled using the software Velvet [30]. The genome of B. subtilis NCD-2 contained 189 contigs (>133 bp; N90, 16,187) of 4,644,322 bp, with an average G+C content of 43.5%. The final assembled genome comprised 4,444 genes, including 4,329 protein-coding genes (418 signal peptide-coding genes), 83 tRNA genes for all 20 amino acids, 30 rRNA genes, and 2 CRISPR repeat genes. A total of nine putative gene clusters responsible for antimicrobial metabolite biosynthesis were identified. These gene clusters included PKS and NRPS genes (Fig. 1).
The taxonomic status of strain NCD-2
At present, 272 B. subtilis genome sequences were deposited in the GenBank database, including 113 whole- and 159 incomplete genome sequences. The genome sizes of the 272 B. subtilis strains ranged from 2.68 Mb to 5.35 Mb, and the GC contents ranged from 42.9% to 46.6%. These genome sequences were downloaded from the GenBank database, and their accession numbers were listed (Additional file 1, Table S1). To analyze the evolution of different B. subtilis strains, a phylogenetic tree was constructed based on the complete genome sequences. The 272 strains of B. subtilis were divided into four subspecies, subtilis, inaquosorum, spizizenii, and stercoris because of producing different bioactive secondary metabolites [31]. As shown in Fig. 2, strain NCD-2 (represented by the black bar) clustered together with B. subtilis strain UD1022 and was closely related to B. subtilis strains XF-1, BAB-1, HJ5, SX01705, and BSD-2.
Secondary metabolite biosynthetic gene clusters in strain NCD-2
The secondary metabolite biosynthetic gene clusters in the genome of strain NCD-2 were predicted using the online website antiSMASH [32]. In total, nine secondary metabolic gene clusters were identified in the NCD-2 genome sequences (Table 1), including three NRPS, two terpenes, one heterozygous NRPS-TransAT PKS-Other KS, one type III polyketide, one sactipeptide-head to tail gene cluster, and a gene cluster with an unknown function. The structural compositions of the gene clusters were shown in Fig. 3. These clusters were composed of core biosynthetic, additional biosynthetic, transport-related, regulatory, and other genes. Among these nine gene clusters, clusters 3, 7, 8, and 9 had 100% amino acid sequence homology with known gene clusters that synthesize bacillaene, bacillibactin, subtilosin, and bacilysin, respectively (Table 1). Gene cluster 1 showed 82% amino acid similarity with a surfactin synthetase gene cluster, and gene cluster 4 showed 93% amino acid similarity with a fengycin biosynthetic gene cluster in B. velezensis strain FZB42. However, gene clusters 2, 5, and 6 did not match any known gene clusters. Clusters 1 and 4 of strain NCD-2 were further compared with those of the model strain 168 and B. subtilis strains closely related phylogenetically to strain NCD-2. The fengycin potentially being coded by biosynthetic gene cluster of strain NCD-2 contained three genes, fenEAB, while the other strains contained five genes, fenCDEAB (Additional file 1, Fig. S1). SrfAB of surfactin was synthesized by the typical transcription and translation of srfAB in the 11 strains. However, the same SrfAB was potentially assembled with Gms0366 and Gms0367 and then transcribed and translated by gms0366 and gms0367 separately in strain NCD-2 (Additional file 1, Fig. S2). Therefore, we hypothesized that the structures and functions of fengycin and surfactin from strain NCD-2 may be different from those of the other B. subtilis strains.
Specificity of surfactin and fengycin synthetase gene clusters in B. subtilis NCD-2
The surfactin biosynthetic gene cluster in strain NCD-2 was analyzed using PRISM, and the core genes were selected for a PKS/NRPS analysis. This gene cluster contained four genes: gms0365, gms0366, gms0367, and gms0368. Gms0365 showed an identical conserved structural and functional domain, CATCATCATe, with SrfAA in strain FZB42, in which C, A, T, and Te represent the condensation, adenylation, thiolation, and thioesterase domains, respectively (Fig. 4a). Compared with SrfAB in strain FZB42, Gms0366 in strain NCD-2 had lost the T and E domains, but the amino acid residues for the binding pockets of Gms0366 were exactly the same as those of SrfAB. The residues of the different adenylation domains A6 and A2 from the enzymes Gms0365 and Gms0366, respectively, were exactly the same, and both bound the amino acid leucine. Gms0367 had only T and E domains, with no specific substrate-binding domain. The superposition of Gms0367 and Gms0366 domains formed a complete SrfAB. The T domain was reversed between Gms0367 and Gms0368. The domains of Gms0368 were CATe, in which the thioesterase domain released linear peptide chains. The domains of Gms0368 were exactly the same as those of SrfAC, but the amino acid residues forming the binding pockets were not completely conserved. The residue sequence was DAF-LGCV, compared with DAFXLGCV of strain FZB42, revealing a difference of one residue.
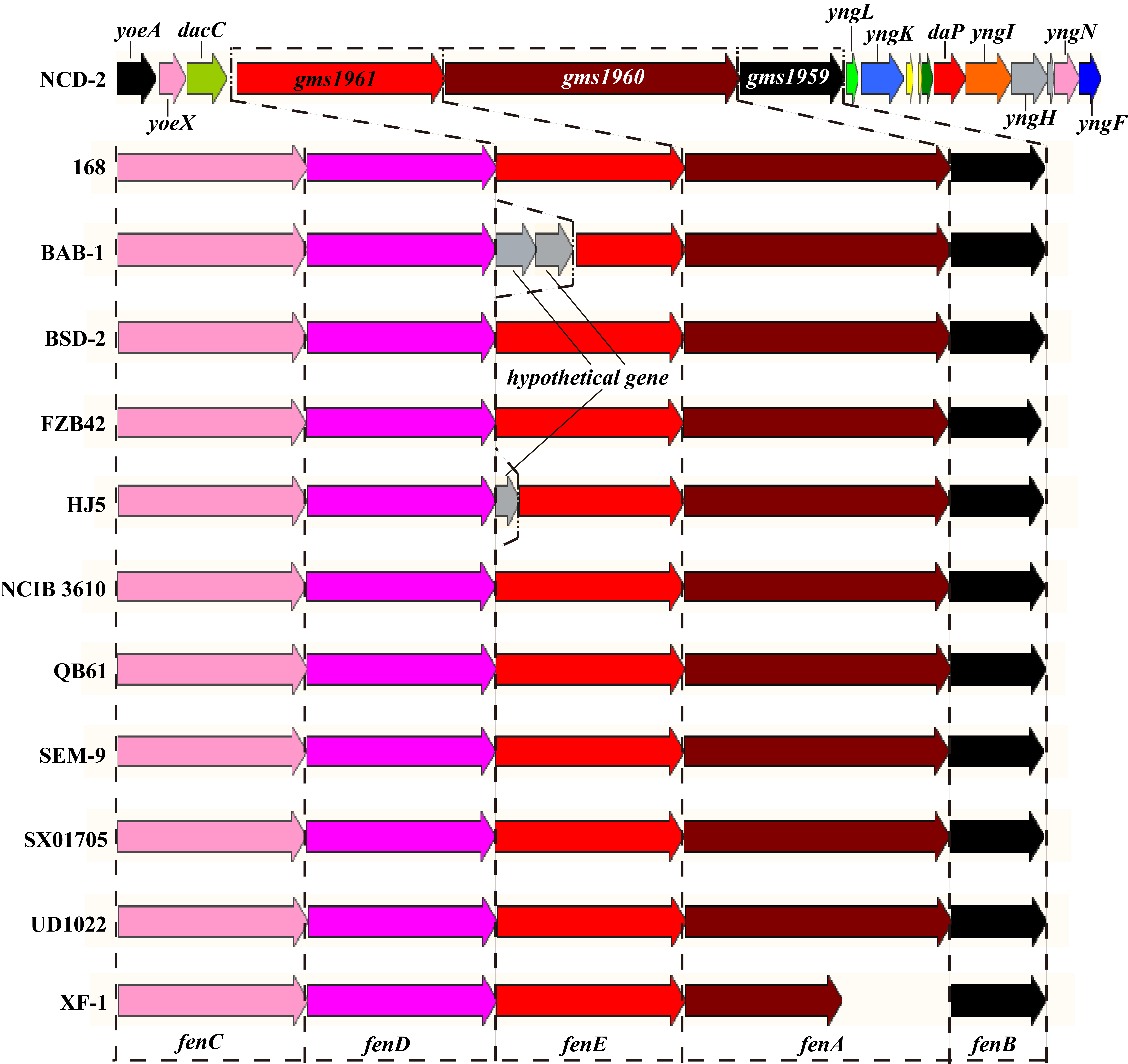
The fengycin biosynthetic gene cluster was analyzed by PRISM, and the core genes were selected for a PKS/NRPS analysis. This cluster contained five genes in strain FZB42’s genome, they were ordered as fenCDEAB (Fig. 4b). However, according to Fig.4b, the fengycin biosynthetic gene cluster in strain NCD-2 contained only three genes: gms1961, gms1960, and gms1959. Gms1961 of strain NCD-2 corresponded to FenE in strain FZB42 had conserved residues of A8 and A9, which bound two amino acids Glu and Val, respectively (Fig. 4b). Gms1960 and Gms1959 in strain NCD-2 had conserved amino acids sequences related to FenA and FenB in strain FZB42, respectively. Interestingly, no homologs of FenC and FenD were identified in the genome of strain NCD-2. Consequently, the amino acid sequences of FenC and FenD from strain FZB42 were compared with the strain NCD-2 proteome using BioEdit. Gms1961 was most similar to FenC, and Gms1960 was most similar to FenD (Additional file 1, Tables. S2, S3). Therefore, it was hypothesized that Gms1961 and Gms1960 performed the functions of FenC and FenD in strain NCD-2, respectively. Thus, Gms1961 and Gms1960 might have dual functions, in details, Gms1961 in strain NCD-2 served as FenE and FenC in strain FZB42, Gms1960 in strain NCD-2 served as FenA and FenD in strain FZB42, in the synthesis of fengycin. However, the FenD domain varied greatly between strain NCD-2 and FZB42, and other enzymes might have similar function as FenD.
To further confirm the unique structure of fengycin synthetase gene cluster in strain NCD-2, a pair of primers that binding the fenE and dacC were designed, the binding sites were identical between strain NCD-2 and FZB42 (Fig. 5a). With the primers set, a 4791 bp fragment was successfully amplified from strain NCD-2, but failed to amplify target the fragment from strain FZB42 due to the larger target fragment (20290 bp) in it (Fig. 5b). The amplicon from strain NCD-2 was purified and ligased to pEASY-Blunt Zero vector (Fig. 5c), and then was sequenced. The sequences alignment confirmed that fenC and fenD were deficient in strain NCD-2 (Fig.5d). The role of gms1961 in the fengycin production was also tested. Strain NCD-2 could produce abundant fengycin, however, the in-frame deletion of gms1961 in strain NCD-2 completely lost the fengycin production (Fig. 6a-c).
To further investigate whether the structure of the fengycin synthetase gene cluster in NCD-2 was strain specific, the fengycin biosynthetic gene clusters from 11 different B. subtilis strains that were closely related to strain NCD-2 or are model strains were compared (Additional file 1, Fig. S1). The gene cluster sequences of all 11 strains were fenCDEAB (also ppsABCDE), and only that of strain NCD-2 was fenEAB. Therefore, the fengycin biosynthetic gene cluster of strain NCD-2 is unique.
MS/MS of fengycin and surfactin in NCD-2
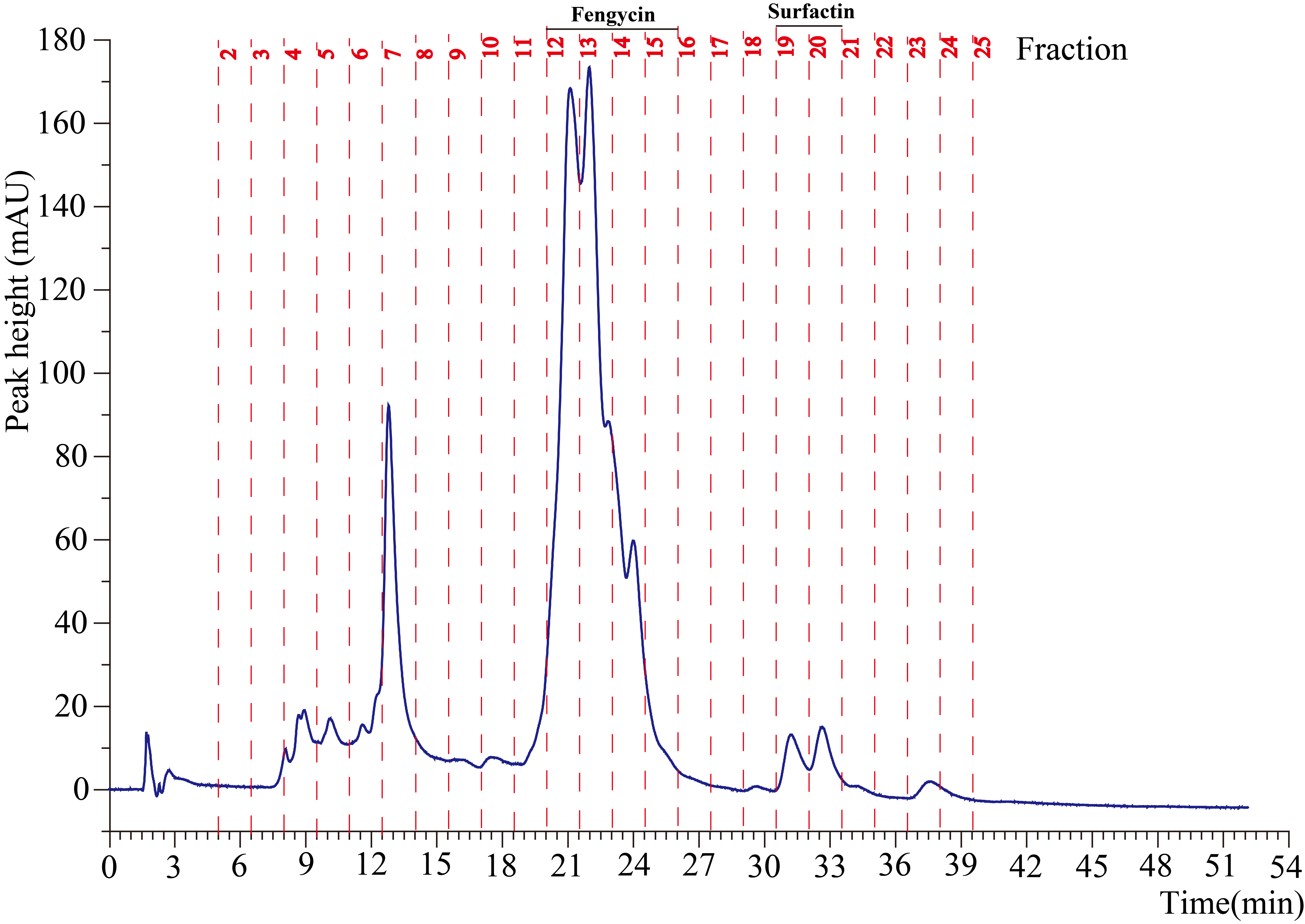
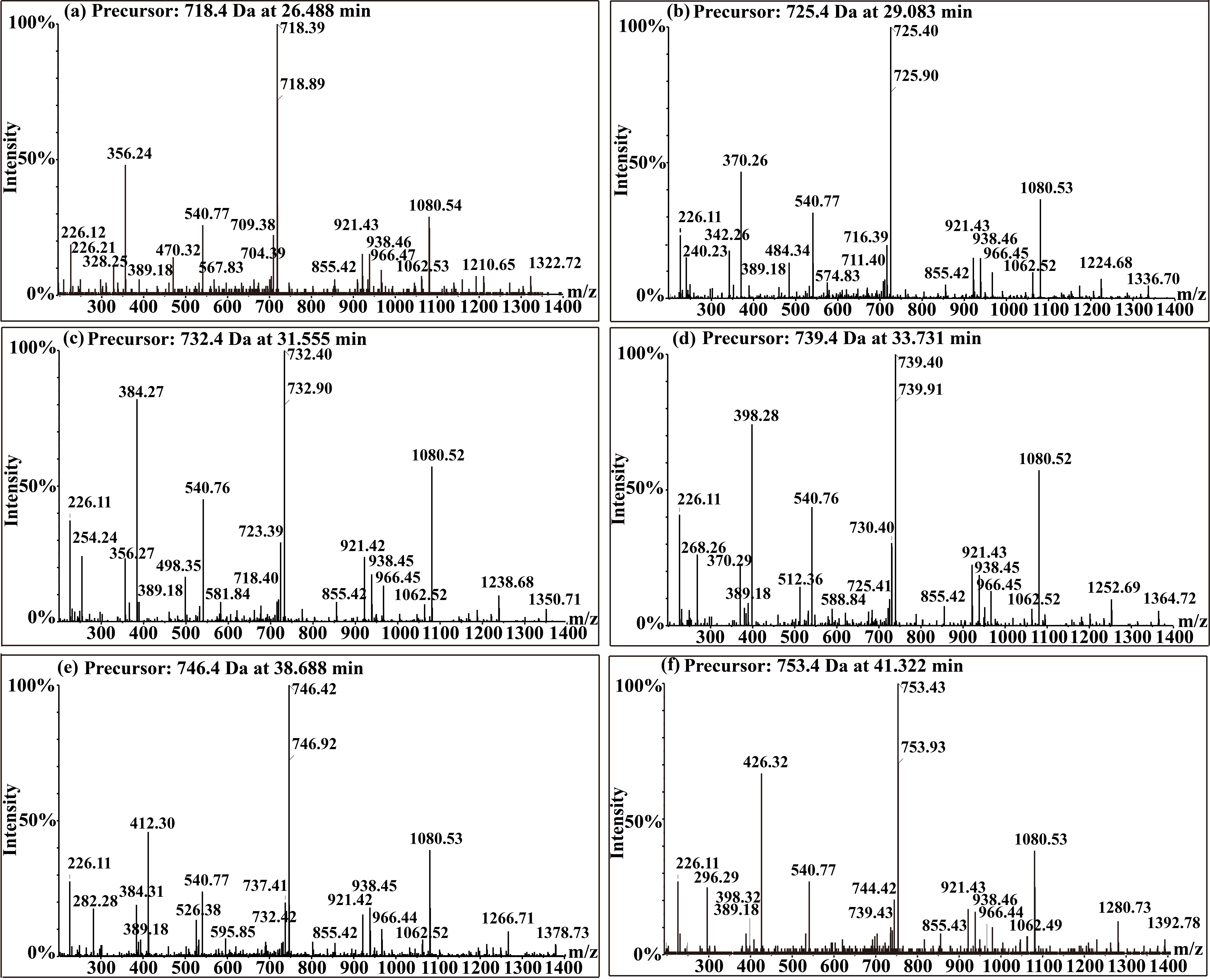
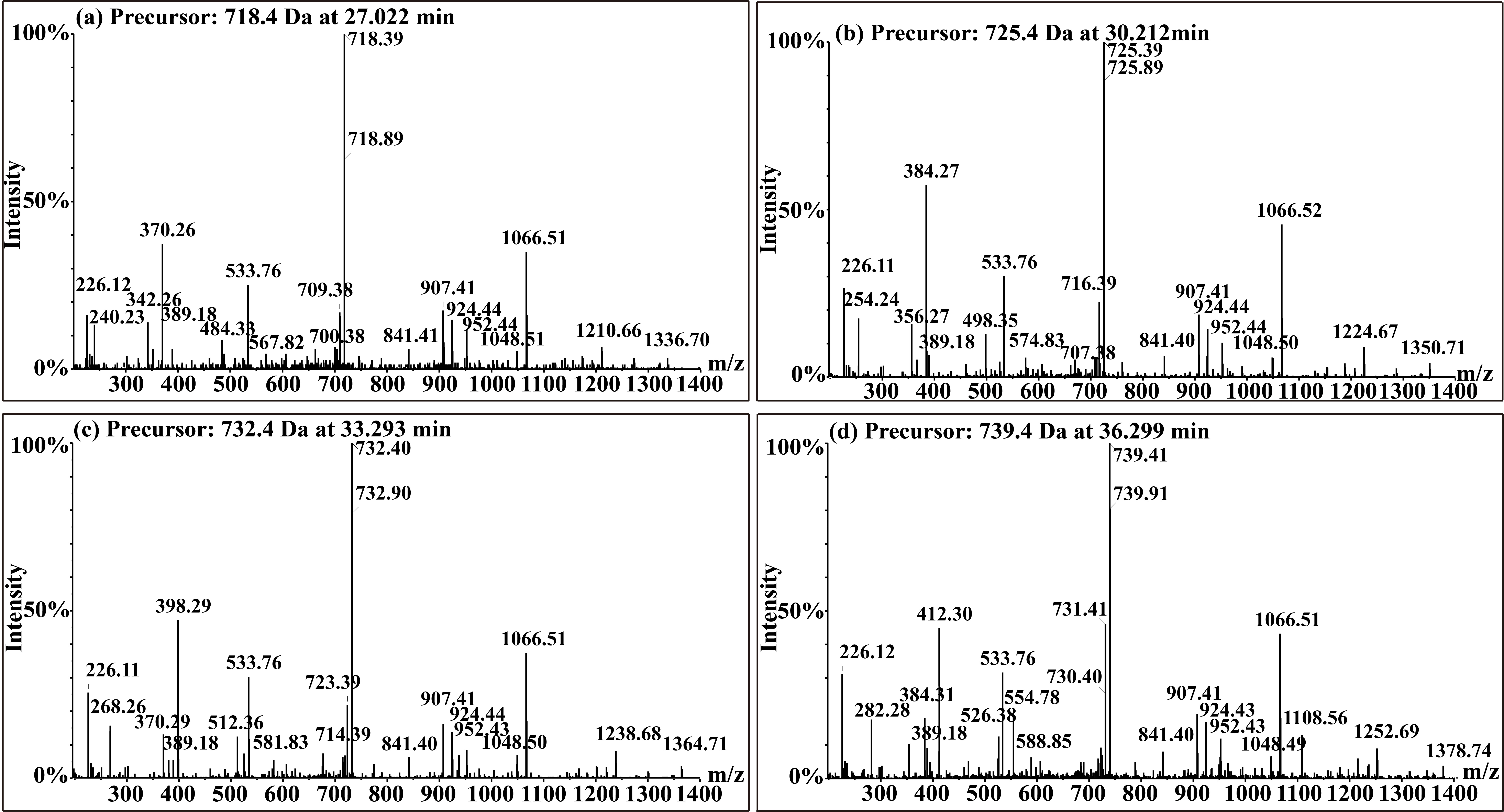
Fengycin was separated from the lipopeptide extract of strain NCD-2 using Fast protein liquid chromatography (FPLC) (Additional file 1, Fig. S3), and the QTOF–MS/MS analysis revealed five fractions in the fengycin cluster (Fig. 7a–e). The five fractions had mass-to-charge ratio (m/z) values of 732.4, 746.4, 725.4, 739.4, and 767.4 (secondary MS), representing fengycin A, fengycin B, fengycin A2, fengycin B2, and fengycin C, respectively. The typical MS/MS spectra showed the distributions of key fragmentation ions (α and β), representing the linear N-terminal and the cyclic C-terminal segments, respectively, of diverse fengycin species (Additional file 1, Fig. S4a-b) and (Fig. 7a–e). The MS/MS spectrum of the fengycin ion at m/z 732.4 yielded two intense product ions at m/z 966.5 and 1,080.5, representing fengycin A (Fig. 5a), while the MS/MS spectrum of the fengycin ion at m/z 746.4 (Fig. 7b) yielded key product ions at m/z 994.5 and 1,108.6, representing fengycin B (Fig. 7b). The MS/MS spectrum of the fengycin ion at m/z 725.4 yielded two intense product ions at m/z 952.4 and 1,066.5, representing fengycin A2 (Fig. 7c), while the MS/MS spectrum of the fengycin ion at m/z 739.4 (Fig. 7d) yielded key product ions at m/z 980.5 and 1,094.5 representing fengycin B2 (Fig. 7d). The MS/MS spectrum of the fengycin ion at m/z 767.4 yielded two intense product ions at m/z 994.5/1,008.5 and 1,108.6/1,122.6 representing fengycin C (Fig. 7e). Five classes of fengycins were identified based on the key product ions of β-hydroxy fatty acid (β-OH FA) with chain lengths varying from C12 to C20 (Table 2, Figs. S5–S9). The MS/MS spectrum of the surfactin ion at m/z 1,008.7 yielded one intense product ion at m/z 685.5 (Fig. 7f; Additional file 1, Fig. S4c). Based on these key product ion, one class of surfactin was identified, which were the surfactins (m/z values of 994.6, 1,008.7, 1,022.7 and 1,036.7) of fatty acids with chain lengths varying from C11 to C15 (Fig. S10).
Detection of other antimicrobial active compounds in NCD-2
Except for the fengycin and surfactin, bacillaene, bacilysin, bacillibactin and subtilosin were also predicted from the genome of strain NCD-2. The four predicted antimicrobial active compounds were extracted from the fermentation broth of strain NCD-2 by using different extracting methods, respectively. However, only bacillaene and bacillibactin were detected from the extracts by UHPLC-QTOF-MS (Fig. 8a, 8b).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}