Study design
This is an observational, cross-sectional, and analytical study conducted with publicly available data from the 1976-1980 NHANES II, a unique source of national data on the health and nutritional status of the US population, aiming to determine the prevalence of major diseases and risk factors for diseases. The methods and data collection procedure behind NHANES are described in detail elsewhere (NCHS, 2023).
Population or sample studied
The NHANES II sample was composed of 27,801 individuals from 6 months to 74 years of age, being that 25,286 were interviewed and 20,322 were examined, resulting in an overall response rate of 73.0% (NCHS, 2023).
Participants who had complete information on the variables of interest were included in this study: skin color, heart attack, self-rated health, sex, body mass index (BMI), total cholesterol, systolic and diastolic blood pressure, and geographic location. Participants who were younger than 18 years old or older than 74 years old, who had a physical or mental disability that prevented data collection, or who had a medical condition that could interfere with the results were excluded. The final sample of this study consisted of 10,351 participants.
Outcome variable
The outcome variable was a heart attack, measured using the following question: “Has a doctor ever told you that you had a heart attack?”. The answer options were: yes (1) or no (0).
Exposure variable
The exposure variable was skin color, and the answer options were: white (1), black (2), or other (3). For analysis purposes, the variable was dichotomized into black (1) or non-black (0), the latter being the reference category.
Covariates
Variables potentially related to the outcome were: sex (male or female), age (20-29, 30-39, 40-49, 50-59, 60-69, and ≥ 70 years), location (urban or rural), diabetes (no or yes), BMI, self-rated health, systolic and diastolic blood pressure, and high blood pressure. Self-rated health was assessed using the question: “Would you say your health in general is?” Responses included five categories: excellent, very good, good, fair, and poor. For this study, the responses were re-categorized as excellent/very good (reference category), good (moderate), and fair/poor based on other studies other studies that analyzed self-rated health (Brett O’Hara & Kyle Caswell, 2010; White, Philogene, Fine, & Sinha, 2009). BMI was evaluated as a continuous variable, calculated as the ratio between weight in kilograms and the square of height in meters. Systolic and diastolic blood pressure were measured using a sphygmomanometer and expressed in millimeters of mercury, and high blood pressure was classified when systolic blood pressure ≥ 140 or diastolic blood pressure ≥ 90.
Statistical analysis
To analyze the data using Stata software version 16.0. The NHANES II database was downloaded from Stata using the 'webuse nhanes2' command. The sampling plan was then checked using the 'svydescribe' command, which confirmed that the 'finalwgt' variable was the sampling weight, the 'strata' variable was the stratum and the 'psu' variable was the primary sampling unit. All statistical analyses were performed considering a 5% significance level and adopting procedures for studies with complex methodologies (cluster sampling and multiple stages). We incorporated the prefix 'svy' (survey commands) into the syntax, which considers the effects of stratification and clustering derived from the complex sampling design, along with the sample weighting, to expand the results to the population evaluated.
The descriptive analyses included absolute and relative frequencies for categorical variables and measures of central tendency and dispersion for continuous variables. For the categorical, the data was tabulated using the following command: 'svy: tabulate variable_category variable_outcome, ci col', which produced a table with the absolute and relative frequencies, 95% confidence intervals (95%CI), and Pearson's chi-squared tests for each category. For the continuous variables, the data was tabulated using the following command: 'svy: mean continuous_variable, over (outcome_variable)' and 'regress continuous_variable, outcome_variable', which produced a table with the means, 95%CI, and the test for statistical significance.
For the multivariate analyses, two approaches were used: the stepwise technique and the DAG-based approach. The stepwise technique is a method that uses predefined criteria to select the variables that remain in the statistical model. In this study, two algorithms were used: forward and backward. In the forward algorithm, the empty model does not contain any variables, and the inclusion of each variable potentially related to the outcome is tested, using the p-value as the model fit criterion. The variable (if any) with the lowest p-value of less than 0.05 is included in the model and the process continues until no other variable reaches this level of significance. In the backward algorithm, the initial model contains all the variables potentially related to the outcome that had a p-value of less than 0.20 in the univariate analysis. These variables are tested for removal from the model, using the p-value as the model fit criterion. The variable (if any) with the highest p-value and which is greater than 0.05 is removed from the model and the process is repeated until all the remaining variables have a p-value of less than 0.05.
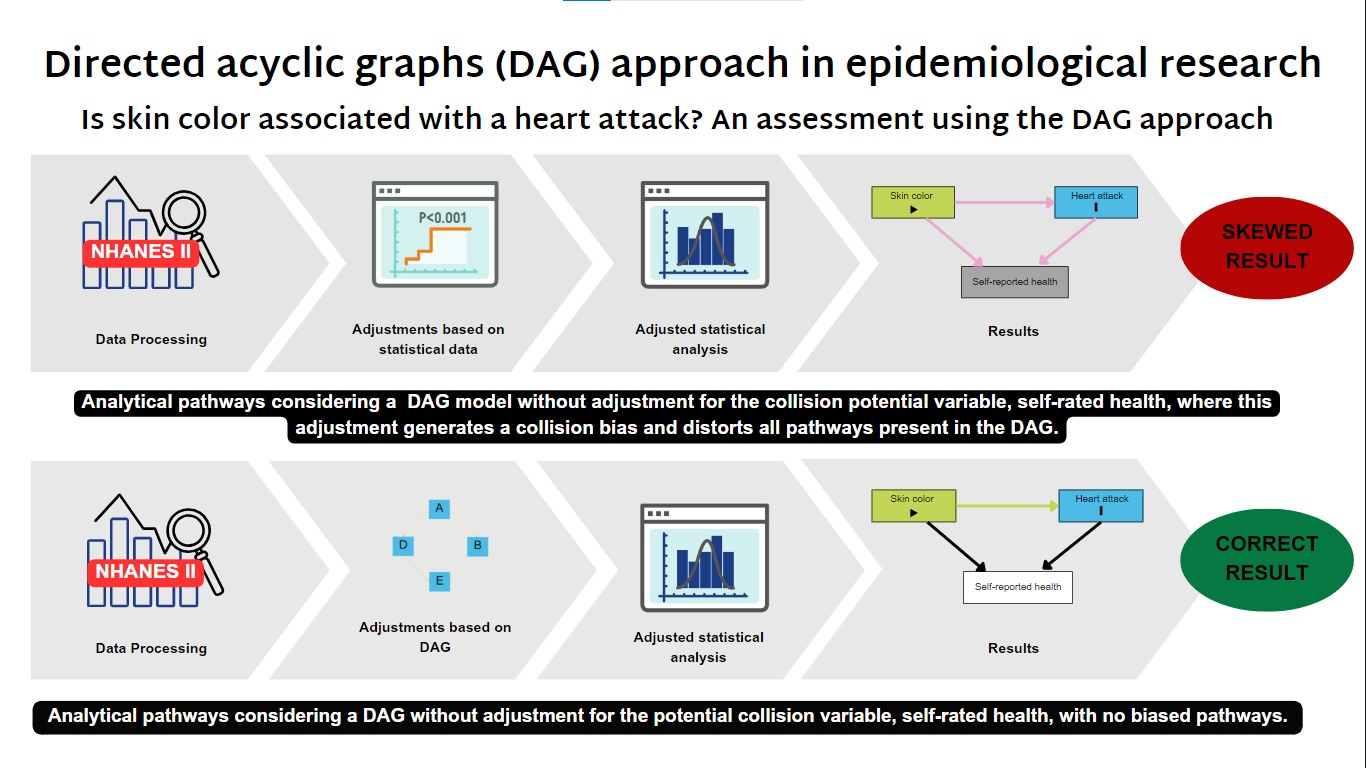
The DAG-based approach is a method that uses causal criteria to select the variables that remain in the statistical model. In this study, different possible causal models between the variables were constructed using DAGitty software version 3.0. To do this, causal connections represented by arrows were established between the variables. Each variable in the DAG was represented with a rectangle, and each color had a different meaning: green, exposure variable; blue, outcome variable; light red, potential confounding variables; white, colliding variable (Figure 1). To avoid spurious associations and unnecessary adjustments, the backdoor criterion was adopted to select the minimum set of confounding variables. A set of variables is considered sufficient for confounding control if the variables contained block all non-causal paths linking exposure to the outcome. In addition, the set must be minimal, as the inclusion of unnecessary variables not only has a risk of causing collision bias but also contributes to reducing the accuracy of the estimates.
To design the DAG and select the path between the explanatory variable (skin color), the outcome (heart attack), and the probable collider (self-rated health), a portfolio with the Hill criteria was made to support the path of analysis, available in the Supplementary Material (Appendices 1, 2, and 3). The Hill criteria are a set of nine aspects that can be used to assess the strength of evidence of a causal relationship between two variables. These aspects are the strength of association, consistency, specificity, temporality, biological gradient, plausibility, coherence, experimental evidence, and analogy. These criteria were applied to verify the path of 1) Skin color to Heart attack; 2) Heart attack to Self-rated health and; 3) Skin color to self-rated health. Then, we can check which scenario is more realistic. It was found that self-rated health can be a mediator or a collider between skin color and heart attack.
After that, in the multivariate analyses, seven logistic regression models were performed using two approaches: the stepwise technique and the DAG-based approach. The seven models were: Model 1: univariate, without adjusting for any variable: 'svy: logistic heartattack i.black'. Model 2: stepwise backward, without considering the colliding variable (self-rated health), adjusted for location, diabetes, and blood pressure: 'svy: logistic heartattack i.black i.rural i.diabetes i.highbp, Model 3: stepwise forward, without considering the colliding variable (self-rated health), adjusted for sex, age, diabetes, and BMI: 'svy: logistic heartattack i.black i.sex i.age i.diabetes c.bmi'. Model 4: based on DAG, for the total effect of skin color on heart attack, without adjusting for any variable, as there was no spurious path opened by the backdoor criterion: 'svy: logistic heartattack i.black'. Model 5: based on DAG, for the direct effect of skin color on heart attack, adjusted for mediators (blood pressure, BMI, diabetes, and location): 'svy: logistic heartattack i.black i.highbp c.bmi i.diabetes i.rural.' Model 6: stepwise backward, considering the collider variable (self-rated health), adjusted for self-rated health and blood pressure: 'svy: logistic heartattack i.black i.hlthstat i.highbp’. Model 7: stepwise forward, considering the collider variable (self-rated health), adjusted for self-rated health, sex, and age: 'svy: logistic heartattack i.black i.hlthstat i.sex i.age'.
{kind=link}