Retrieval and Identification of WD40 Genes in pepper
In this paper, the candidate WD40 proteins were retrieved as follows: firstly, the protein, nucleotide and genome sequences of the Zunla, CM334 and zhangshugang genomes were download the Sol genomics Network (https://solgenomics.net/organism/Capsicum_annuum/genome) [52, 53] and pepper Genomics Database (http://ted.bti.cornell.edu/cgi-bin/pepper/index) [31], respectively. Secondly, the Hidden Markov model (HMM) of WD40 protein (PF00400) was downloaded from the Pfam database (http://pfam-legacy.xfam.org/) [54]. Furthermore, the HMMER (v3.0) software [55] was employed to search the predicted WD40 proteins using the cut-off value of the default parameter. Finally, all these potential members were examined for the WD40 domain in InterPro (https://www.ebi.ac.uk/) [56] and SMART database (http://smart.embl-heidelberg.de/smart/batch.pl) [57], and those without the complete WD40 domain were manual deletion.
Sequence analysis and structural characteristics
Protein length, molecular weight and theoretical isoelectric point ( pIs) of CaWD40 proteins were analyzed using the Expasy tool (https://web.expasy.org/compute_pi/) [58]. The supposed subcellular localization of CaWD40 proteins were predicted by the online tool WOLF PSORT (https://wolfpsort.hgc.jp) [59]. The protein sequences were submitted to MEME program (https://meme-suite.org/meme/tools/meme) [60] to investigate conserved motifs.
Chromosome Localization and tandem duplication
Chromosome locations and gene position was obtained via searching the pepper of Sol genomics Network. Chromosome mapping of the CaWD40 gene family was displayed by MG2C (http://mg2c.iask.in/mg2c_v2.1) [61]. The tandem duplication events was also further confirmed with the following criteria: (1)the alignment length had a coverage rate more than 70% of the full length of the CaWD40 genes; (2) the identity of the aligned region was over 70%; (3) and an array of two or more genes was less than 100 kb distance.
Phylogenetic Analysis
The phylogenetic tree was produced in the following three steps: firstly, the CaWD40 protein sequences were imported into Clustal X to produce a multiple sequence alignment file. Secondly, the alignment result was used to build an unrooted tree using MEGA11 with a bootstrap of 1000 replicates and neighbor-joining (NJ) methods [62]. Thirdly, the newly produced phylogenetic tree was visualized using the Interactive Tree of Life online website (https://itol.embl.de/) [63].
RNA-Seq analysis of CaWD40 Genes
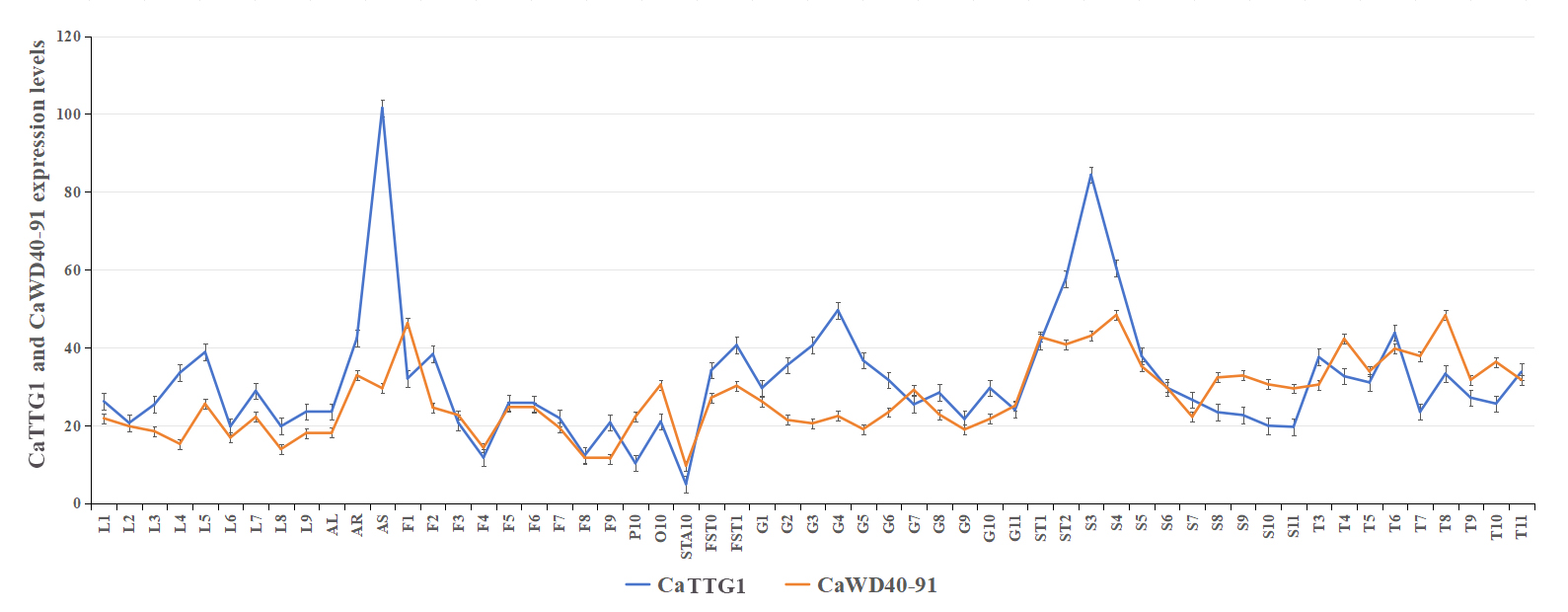
To get insight into the expression profiles of the CaWD40 gene family in different tissues at different periods, Transcriptome sequencing (RNA-seq) data of development was used to explore the distribution of gene expression in pepper (the elite Capsicum line 6421) [64]. Expression levels were determined in the following tissues and stages: Leave tissues were sampled at 2, 5, 10, 15, 20, 25, 30, 40, 50 and 60 days after emergence, and marked as L1, L2, L3, L4 and L5, L6 and L7, L8, L9, and AL; Floral buds were sampled at 0.25, 0.35, 0.5, 0.8, 1.0, 1.2, and 1.7 cm, and marked as F1, F2, F3, F4 and F5, F6 and F7, F8, and F9; Petals, stamens, and ovaries with stigmas were sampled at fully blossomed flowers, and marked as P10, STA10 and O10; Fruits were collected at 3, 7, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55 and 60 days after flowering (DAF), and flagged as FST0, FST1, G1, G2, G3, G4, G5, G6,G7, G8, G9, G10, G11; Seed samples were collected at 10, 15, 20, 25, 30, 35, 40, 45, 50, 55 and 60 DAF, and flagged as ST1, ST2, S3, S4, S5, S6, S7, S8, S9, S10, S11; Placenta samples were collected at 20, 25, 30, 35, 40, 45, 50, 55 and 60 DAF, and flagged as T3, T4, T5, T6, T7, T8, T9, T10, and T11. In addition, stems and roots were tagged as AS and AR, respectively. The treatment methods of all samples refer to the article published by Liu et al. [64]. All data of CaWD40 genes were normalized (log2(FPKM + 1)), and a heat map was drawn using TBtools-Ⅱ (v2.019) [65].
RNA extraction and RT-qPCR analysis
Capsicum line 6421 plants were grown at 27 ℃/22 ℃ day/night cycles under a 16/8 h (light/dark) photoperiod. Total RNA was extracted using the TransZol Up (TransGen, China) and reverse-transcribed using RevertAid First Strand cDNA Synthesis Kit (Thermo Scientific, China). The RT-qPCR was carried out using 2 × ChamQ Universal SYBR qPCR Master Mix (Vazyme, China) on a LightCycle® 96 Real-Time PCR System (Roche, Switzerland).
The UBI-3 gene was used as a reference gene [66]. Gene-specific primers were designed and were listed in Table S1. The RT-qPCR was performed based on three biological repeats and three technical repeats, and relative expression level of each gene was calculated using the 2−ΔΔCt method.
Yeast two-hybrid (Y2H) assays
Using specific primer pair, the coding sequences of CaWD40-91, CaAN1, CaDYT1 and CaGL3 were amplified and inserted into pGBKT7 and pGADT7 vectors, respectively (Table S1). Four plasmids, pGBKT7-CaWD40-91, pGADT7-CaAN1, pGADT7-CaDYT1 and pGADT7-CaGL3 were extracted and co-transformed into Y2HGold receptor cells (WEIDI, China). All the transformation products were plated and grown on SD/-Trp/-Leu medium for three days. Protein-protein interactions were further detected on the SD/-Trp/-Leu/-His/-Ade selective medium based on the Matchmaker® Gold Yeast Two-Hybrid System User Manual.
Dual-luciferase reporter assays
The primers of Nluc-CaWD40-91, Cluc-CaAN1 and Cluc-CaDYT1 were designed (Table S1). The CaWD40-91 was cloned and inserted into the pCambia1300-NLUC, CaAN1 and CaDYT1 were cloned, then inserted into pCambia1300-Cluc by linearized with KpnI and SalI. These recombinant plasmid were further transferred into Agrobacterium tumefaciens GV3101. Mixture was infiltrated into tobacco leaves, and fluorescence signal was captured three days after infiltration using Vilber Fusion FX7 Spectra device system (Vilber Bio Imaging, Paris, France). Nluc-EV and Cluc-EV were used a controls.
{kind=link}
{kind=link}
{kind=link}