In recent years, various seismic wave arrival time picking models using deep learning have been developed (Ross et al., 2018; Zhu and Beroza, 2019; Mousavi et al., 2019; Zhu et al., 2022; Tokuda and Nagao, 2023; Sun et al., 2023). It has been reported that PhaseNet (Zhu and Beroza, 2019) outperforms traditional arrival time picking methods using AR-AIC (Sleeman and Van Eck, 1990) in accuracy. Furthermore, when comparing deep learning models, Generalized Phase Detection (GPD; Ross et al., 2018), PhaseNet and EQTransformer (Mousavi et al., 2019) performed well (Münchmeyer et al., 2022). Garcìa et al. (2022) compared the above three models. They reported that GPD has a high arrival time detection capability but many false positives, EQTransformer has a low arrival time detection capability but few false positives, and PhaseNet has an intermediate performance between GPD and EQTransformer. Garcìa et al. (2022) concluded that combining PhaseNet and phase association has the best earthquake detection performance for earthquake cataloging.
Deep learning models for arrival time picking can be divided into two categories. The first category is single-station models that input seismic waveforms observed at a single station and determine arrival times of P-waves and S-waves. This approach, used by PhaseNet and EQTransformer, focuses on data obtained from individual observation points. The second category is multi-station models that input seismic waveforms observed at multiple stations and determine the arrival times of P-waves and S-waves for each waveform. This approach, used by EdgePhase (Feng et al., 2022) and PhaseNO (Sun et al., 2023), focuses on using information from entire observation networks by integrating data from different locations. Single-station models can learn local features of seismic waveforms, while multi-station models can learn information from the wave field.
Accuracy is essential for creating earthquake catalogs using an arrival time-picking deep learning model. While it may be more effective to consider multiple stations when detecting earthquakes from continuous waveforms (Yano et al., 2021), it is important for earthquake detection using arrival times picked by a deep learning model to be able to achieve accurate picking. When creating a seismic catalog using a deep learning model, the process involves three primary steps. First, arrival times are picked from observed continuous seismic waveforms. Second, arrival times corresponding to the same earthquake are grouped together; this process is known as phase association. Finally, earthquake localization is performed. Hence, regardless of the model category, the accuracy of picking arrival times is crucial for earthquake detection using arrival time picking deep learning models.
The accuracy of arrival time picking models depends on the data used for training. It has been reported that differences between the regions used for training and application can degrade picking accuracy, and adapting models trained on three-component waveforms to only vertical-component waveforms can result in decreased accuracy (Münchmeyer et al., 2022). Moreover, deep learning models for polarity determination perform differently depending on the sampling frequency and observed location (Hara et al., 2019). Therefore, preparing models trained on seismic waveforms obtained in the application area, matching sampling frequencies, and waveform components can improve picking accuracy.
Dense seismic observation networks like the Manten network (Miura et al., 2010; Iio, 2011; Iio et al., 2017) and Metropolitan Seismic Observation network (Sakai and Hirata, 2009; Aoi et al., 2021), and temporary aftershock observation in Japan, in addition to stationary seismic observation networks like Hi-net (Okada et al., 2004; Obara et al., 2005; Shiomi et al., 2009), currently exist. Stationary seismic observation networks composed of seismometers sampling at 100 Hz in three components. The Manten seismic observation network, composed of seismometers sampling at 250 Hz in three components, has been deployed in the central and northern Kinki region, western Nagano region including the source region of the 1984 western Nagano prefecture earthquake, and the San-in region including the source region of the 2000 western Tottori prefecture earthquake, from 2009 to 2022. The Manten network has many observation stations: 80 in the Kinki region, 31 in Nagano, and 125 in the San-in area, making it a very dense network. Additionally, a temporary aftershock observation network called the 0.1 Manten network was installed in the source regions of the 2000 western Tottori prefecture earthquake (Matsumoto et al., 2020; Hayashida et al., 2020). The 0.1 Manten network consisted of 1000 seismic stations sampled at 100 Hz with only the vertical component. In addition, temporary aftershock observations were carried out in the aftershock areas of the 2016 Central Tottori Earthquake and the 2018 Northern Osaka Earthquake using seismic station used at the 0.1 Manten network (Iio et al., 2021). These networks have recorded a large volume of high-quality data, which has been utilized in various studies (Aoki et al., 2016; Katoh et al., 2018; Yukutake et al., 2020; Hayashida et al., 2020; Iio et al., 2021). Due to the high-density and long-term observations conducted, a large volume of recorded seismic waveforms exists. However, a significant amount of data remains in which earthquake detections and travel times have not been picked by humans. Dense and long-term seismic observation networks like the Manten observation network are globally rare and represent datasets that can contribute to understanding seismic activity and crustal structure. Therefore, comprehensively analyzing this dataset is meaningful.
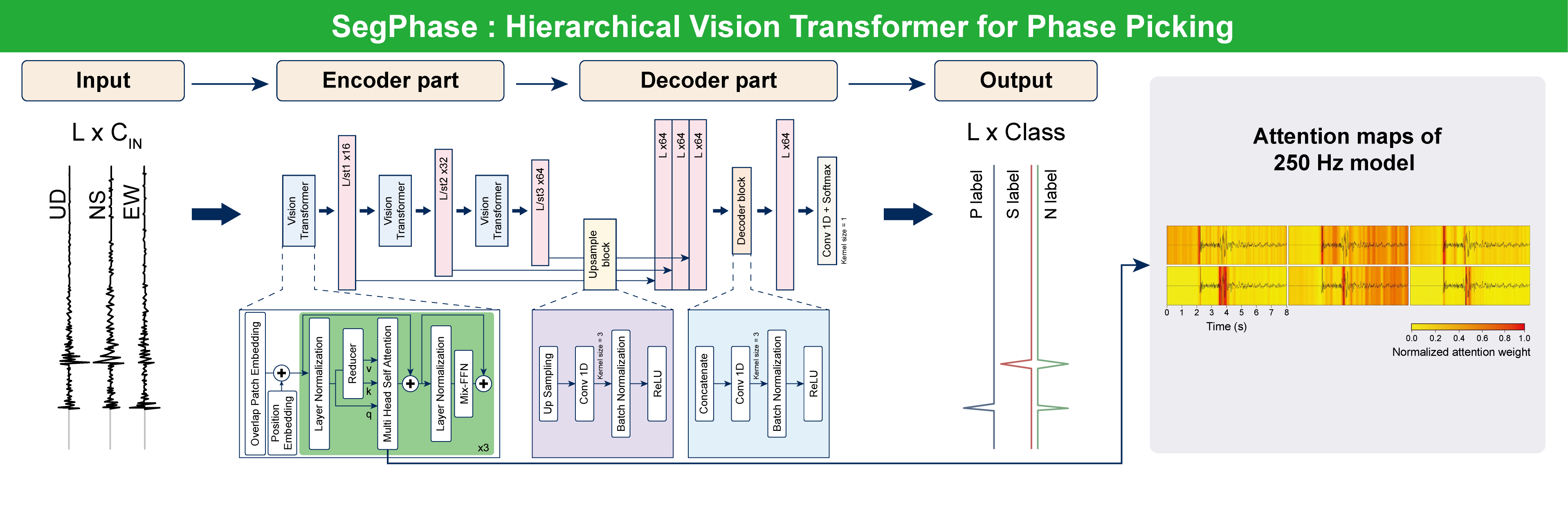
This study developed a new seismic wave arrival time picking model suitable for the Manten observation network, aftershock observation networks above, and stationary observation networks such as Hi-net near the Manten and aftershock observation networks. Since the sampling frequency and the number of observation components differ in each observation network, three models were created: a model for the stationary observation network with 100 Hz sampling in three components (100 Hz model), a model for the Manten observation network with 250 Hz sampling in three components (250 Hz model), and a model for the 0.1 Manten network with only vertical components and 100 Hz sampling (M01 model).
The model structure developed in this study, called SegPhase, differs from previously reported arrival time picking model structures. The SegPhase uses a hierarchical Vision Transformer (ViT; Dosovitskiy et al., 2021) structure similar to Segformer (Xie et al., 2021). ViT applies the Transformer (Vaswani et al., 2017) used in large language models like ChatGPT (Brown et al., 2020) to image recognition models. The previous arrival time picking models primarily used convolutional layers in the encoder part for feature acquisition. On the other hand, our model structure introduces a novel approach by employing three ViT layers exclusively in the encoder for feature acquisition.
ViT is known to be more accurate than convolutional models (Dosovitskiy et al., 2021). Models using ViT and the Convolutional layer have different recognition characteristics. The convolutional layer has a narrow receptive field as it extracts features within the convolutional kernel. On the other hand, ViT has a wide receptive field as it extracts features from the entire input data. Therefore, the Convolutional layer is texture-oriented, while ViT is shape-oriented. The shape-oriented recognition characteristic is close to the human recognition characteristic, meaning ViT performs feature extraction closer to humans than the convolutional layer (Tuli et al., 2021).
We conducted a comparative analysis of picking performance using PhaseNet to evaluate SegPhase. Additionally, we utilized continuous waveform data from the aftershock observation network, which was installed in the source region of the central Tottori prefecture earthquake on October 21, 2016, to compare the number of detected earthquakes. A comprehensive comparison was made between earthquake catalogs generated by SegPhase and PhaseNet which was trained using the same dataset as SegPhase, the Horiuchi program (Horiuchi et al., 2013), and the Japan Meteorological Agency (JMA). This comparison facilitated discussions on the number of detected earthquakes and the accuracy of their hypocenter location based on the output probability threshold.
A package that we created to create a seismic catalog using SegPhase models can directly input WIN files which are a widely used file format in Japan (Urabe, 1994). Although pre-trained deep learning arrival time picking models are available such as PhaseNet and EQTransformer, when using those models to pick the arrival time of seismic waves contained in WIN files, it was necessary to convert them to files such as npy or npz (specific to the python package numpy; Haris et al., 2020). This conversion consumes time and storage space. Our package, however, can directly input WIN files, thereby saving both time and storage space.
In this study, we have developed a new seismic wave arrival time picking model, SegPhase, aimed at efficiently analyzing the vast amount of seismic waveform data obtained from the Manten network and surrounding stationary observation networks such as Hi-net. The primary objective of utilizing deep learning models for picking arrival times is to automate the picking process and the creation of earthquake catalogs. Picking arrival time is most important in seismological research. Thus, our goal is to enhance the accuracy and efficiency of arrival time analysis. Unlike conventional models that use convolution layers for feature extraction, SegPhase employs a hierarchical Vision Transformer, which performs feature extraction in a manner more akin to human recognition. Vision Transformers are more accurate than models that use convolution layers, possessing recognition characteristics closer to those of humans. Therefore, SegPhase is expected to achieve higher accuracy than traditional convolution-based arrival time picking models. We detail the design, implementation, and performance advantages of SegPhase through comparative analysis with PhaseNet.
{kind=link}