Subjects
This retrospective study included 3,485 sequential patients (mean age ± SD, 63.9 ± 13.6 y; range, 24-95 y) who underwent whole-body FDG PET/CT (Table1). All patients were scanned on either Scanner 1 (N=2,864, a Biograph 64 PET/CT scanner, Asahi-Siemens Medical Technologies Ltd., Tokyo) or Scanner 2 (N=621, a GEMINI TF64 PET/CT scanner, Philips Japan, Ltd., Tokyo) at our institute between January 2016 and December 2017.
The institutional review board of Hokkaido University Hospital approved the study (#017-0365) and waived the need of written informed consent from each patient because the study was conducted retrospectively.
Labeling
An experienced nuclear medicine physician classified all cases into 3 categories: 1) benign, 2) malignant and 3) equivocal, based on the FDG PET maximum intensity projection (MIP) images and diagnostic reports. The criteria of classification were as follows.
1) The patient was labeled as malignant when the radiology report described any malignant uptake masses and the labeling physician confirmed that the masses were visually recognizable.
2) The patient was labeled as benign when the radiology report described no malignant uptake masses and the labeling physicians confirmed that there were no visually recognizable uptake indicating malignant tumor.
3) The patient was labeled as equivocal when the radiology report was inconclusive between malignant vs. benign and the labeling physician agreed with the radiology report. In case the labeling physician disagreed with the radiology report, the physician further investigated the electric medical record and categorized the patient into malignant, benign, or equivocal.
Finally, 1,280 (37%) patients were labeled "benign", 1,450 (42%) "malignant" and 755 (22%) "equivocal". Note that the number of malignant label was smaller than the number of pretest diagnosis in Table 1, mainly because Table 1 includes patients who were suspected of recurrence of the particular cancer but showed no malignant findings on PET.
The location of any malignant uptake was determined as A) head and neck, B) chest, C) abdomen, D) pelvic region. For the classification, the physician was blinded to the CT images and parameters such as maximum standardized uptake value (SUVmax). Diagnostic reports were made based on several factors including SUVmax, diameter of tumors, visual contrast between the tumors, location of tumors, and changes over time by 2+ physicians each with more than 8 years’ experience in nuclear medicine.
Image acquisition and reconstruction
All clinical PET/CT studies were performed with either Scanner 1 or Scanner 2. All patients fasted for ≥6 hr before the injection of FDG (approx. 4 MBq/kg), and the emission scanning was initiated 60 min post-injection. For Scanner 1, the transaxial and axial fields of view were 68.4 cm and 21.6 cm, respectively. For Scanner 2, the transaxial and axial fields of view were 57.6 cm and 18.0 cm. Three-min emission scanning in 3D mode was performed for each bed position. Attenuation was corrected with X-CT images acquired without contrast media. Images were reconstructed with an iterative method integrated with (Scanner 1) or without (Scanner 2) a point spread function.
Each reconstructed image had a matrix size of 168 × 168 with the voxel size of 4.1 × 4.1 × 2.0 mm for Scanner 1, and a matrix size of 144 × 144 with the voxel size of 4.0 × 4.0 × 4.0 mm for Scanner 2. MIP images (matrix size 168 × 168) were generated by linear interpolation. MIP images were created at increments of 10-degree rotation for up to 180 or 360 degrees. Therefore, 18 or 36 angles of MIP images were generated per patient. In this study, CT images were used only for attenuation correction, not for classification.
Convolutional neural network (CNN)
A neural network is a computational system that simulates neurons of the brain. Every neural network has input, hidden, and output layers. Each layer has a structure in which multiple nodes are connected by edges. A “deep neural network” is defined as the use of multiple layers for the hidden layer. Machine learning using a deep neural network is called “deep learning.” A convolutional neural network (CNN) is a type of deep neural network that has been proven to be highly efficient in image recognition. A CNN does not require predefined image features. We propose the use of a CNN to classify the images of FDG PET examination.
Architectures
In this study, we used a network model with the same configuration as ResNet [15]. In the original ResNet, the output layer was classified into 1000 classes. We modified the number of classes to 3. We used this network model to classify whole-body FDG PET images into 1) benign, 2) malignant and 3) equivocal categories. Here we provide details on CNN architectures with the techniques used in this study. The detailed architecture is shown in Figure 1 and Table 2. Convolution layers create feature-maps that extract image features. Pooling layers have the effect of reducing the amount of data and improving the robustness against misregistration by down-sampling the obtained feature-map. "Residual" is a block that can be said to be a feature of ResNet that combines several layers, thereby solving the conventional gradient disappearance problem. Each neuron in a layer is connected to the corresponding neurons in the previous layer. The architecture of the CNN used in the present study contained five convolutional layers. This network also applied a rectified linear unit (ReLU) function, local response normalization, and softmax layers. The softmax function is defined as follows: (see Equation 1 in the Supplementary Files)
Model training and testing
Experiment 1 (Overall): First, input images were enlarged to (224, 224) pixels to match the input size of the network. After that, we trained the CNN using data from the FDG PET images. The CNN was trained and validated using 70% patients (N=2440) which were randomly selected. After the training process, the remaining 30% patients (N=1045) were used for testing. A 5-fold cross-validation scheme was used to validate the model. Subsequently, we tested the model. In the model-training phase, we used “early stopping” and “dropout” to prevent overfitting. Early stopping is a function used to monitor the loss function of training and validation and to stop the learning before falling into excessive learning.[16] Early stopping and dropout have been adopted in various machine-learning methods.[17, 18]
Experiment 2 (Region-based analysis): In this experiment, the neural network having the same architecture were trained using 4 datasets consisting of differently cropped images: (A) head and neck, B) chest, C) abdomen, and D) pelvic region, respectively. The label was malignant when the malignancy existed in the corresponding region. The label was equivocal when the equivocal uptake existed in the corresponding region. Otherwise, the label was benign. The configuration of the network was the same as in Experiment 1.
Experiment 3 (Grad-CAM[19]): We carried out additional experiments using the Grad-CAM technique, which visualizes the part activating the neural network. In other words, Grad-CAM highlights the part of the image that the neural network responds to. The same image as the original image used in Experiment 1 was used as the input image.
Hardware and software environments
This experiment was performed under the following environment:
OS, Windows 10 pro 64 bit; CPU, intel Core i7-6700K; GPU, NVIDIA GeForce GTX 1070 8GB; Framework, Keras 2.2.4 and TensorFlow 1.11.0; Language, Python 3.6.7; CNN, the same configuration as ResNet; Optimizer, Adam [20].
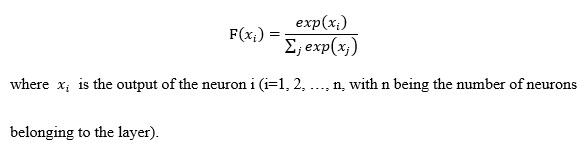{kind=link}