This study was approved by the Institutional Review Board of the Catholic University of Korea, College of Medicine (SC17RCDI0074).
Development of Machine-Learning Algorithm Using Probabilistic Decision Tree
According to Bayes’ theorem, the post-event probability can be calculated when the pre-event probability is given. Bayes’ theorem is stated mathematically as P(B)≠0, where A and B are events[16]. P(A|B) and P(B|A) are the conditional probabilities, such that the likelihood of event A occurring, given that B has occurred and vice versa, respectively. P(A) and P(B) are the probabilities of observing A and B independently of each other[16].

The probabilistic decision tree is one of the predictive modelling approaches used in statistics and data mining. It is often used for machine-learning algorithms, especially when the test node results are binary (Fig. 1). We adopt this approach for our machine-learning algorithm, because the IHC results are binary, and the calculated probabilities can be put together into a database.
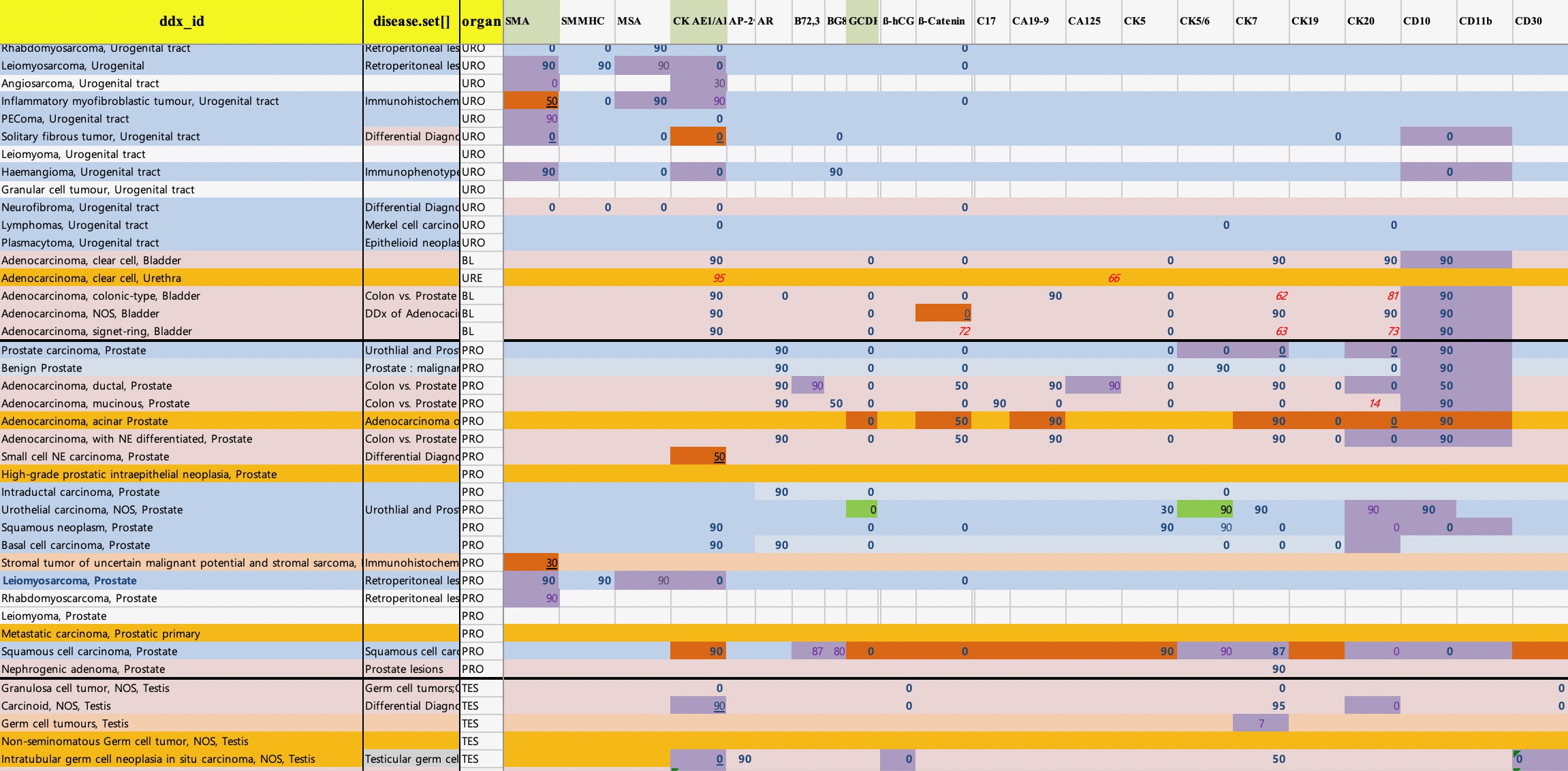
To apply the probabilistic decision tree algorithm, we need a database of a 2 × 2 table with tests, diseases, and the probability of positivity of each test for each disease (Fig. 2). Test results obtained are binary. The probability of positivity signifies the number of positive cases among all the cases of the disease. Once the test results are obtained, the probability for each disease can be calculated by multiplying the prior probability and the probabilities of each test being positive or negative, to indicate the illness with the highest probability, by comparing post probability.
Construction of IHC Database
As shown in Supplementary Table 1, important textbooks on IHC such as Classification of Tumours Series (IARC, Lyon, France) and literature from World Health Organization (WHO), were used to build an IHC database based on the IHC expression profile of all tumours[4, 5, 17-28]. Over 5000 different neoplasms were recorded based on the WHO classification. Neoplasms without IHC expression profile were excluded. Differences in the IHC profile of tumour subtypes, were recorded separately from the primary type.
Each tumours IHC positivity was recorded as showed in the textbook. If there was no exact numerical value attributed to the positivity, arbitrary expressions such as “always positive”, “often positive”, or “rarely/ occasionally positive” were assigned. The positivity of each tumour was described as: “always”: 95 %; “often”: 75 %; “in about a half of cases”: 50 %; “seldom”: 30 %; “rarely/ occasionally”: 10 %; and “never”: 0 %. If the positivity differs between textbooks, the average value was used in the database. IHC database showed in Supplementary Fig 1.
Around 600 antibody names and their synonyms used in IHC were recorded using the textbooks and reviewed with the online references Supplementary Table 2.
Development of ImmunoGenius, A Mobile Application for iOS and Android
The “ImmunoGenius” mobile application for iOS and Android was developed using NoSQL (Fig. 3) and can be accessed on iPhones, Android phones, and iPads. It is designed to search for diseases and upon selection of the illness it generates a table with the IHC antibody names in the first row and disease name in the left column. The IHC profiles are showed in the corresponding cells designated as “++” for 75-100% positivity, “+” for 50-74%, “+/-” for 30-49%, “-/+” for 10-29%, and “–” for 0-9% shown with graded shades (Fig. 4). Individuals can compare the different IHC profiles and add or remove the diseases and IHC antibodies to customize the table. Importantly, individuals can add their IHC results through a button on the right-hand side. Once the IHC results are inserted, the diagnosis presumption algorithm calculates the top 10 most probable diagnoses, which are shown along with the estimated probability (red numbers). The detailed user instructions and software download is available at homepage: https://immunogenius.wixsite.com/website
google play store: https://play.google.com/store/apps/details?id=com.dasomx.ig&hl=ko
you tube video: https://youtu.be/E-PTdMNexOc
Validation of Diagnosis Presumption Algorithm Using Patient Data
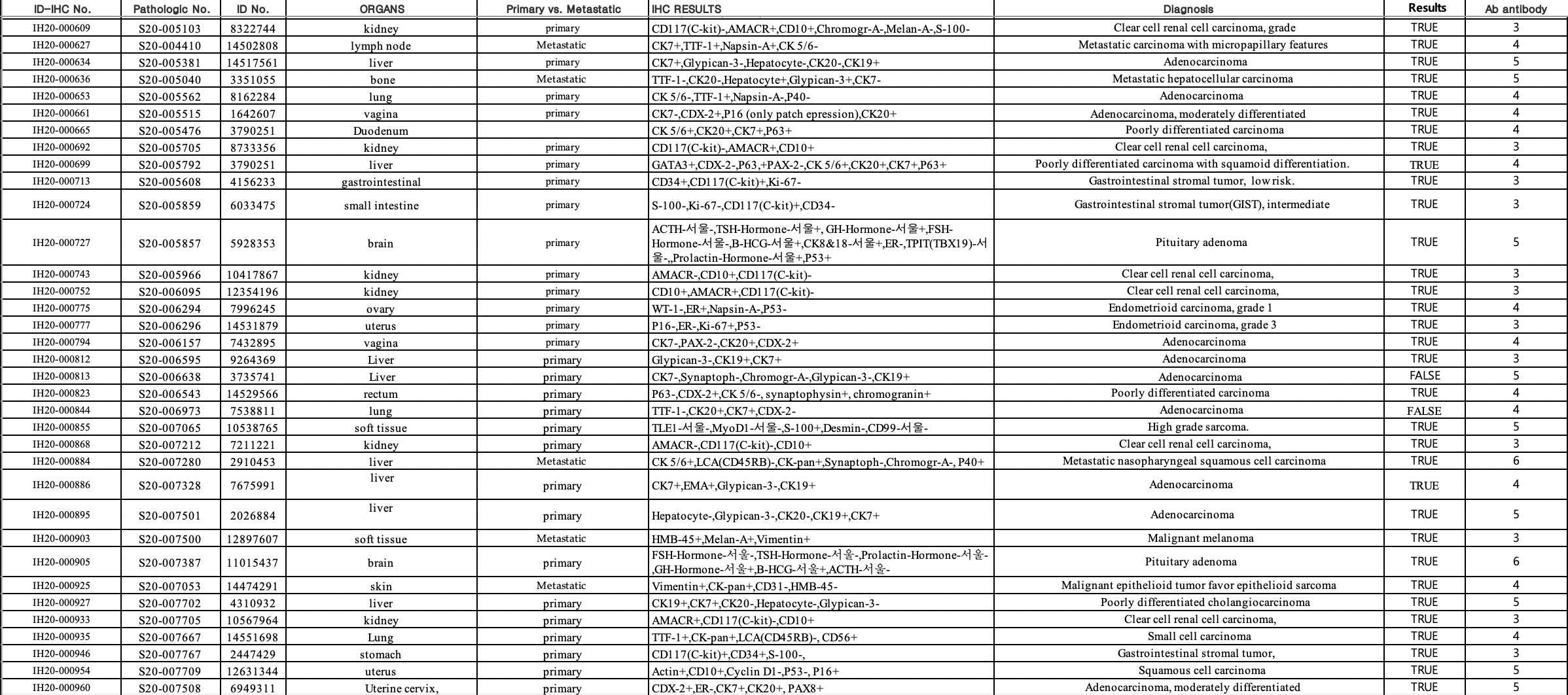
To prove the precision of the diagnosis presumption algorithm, IHC profile data was generated for specific cases and diagnosed by pathologists using conventional methods. These were then compared with the top 10 results from the presumptive diagnoses algorithm. The IHC profile data of 1000 tumours of unknown origin (TUOs) collected between 2010 to 2017 from the Yeouido and Seoul St. Mary’s Hospital, College of Medicine, The Catholic University of Korea were used in this study. Any data related to patient identification, except the original diagnosis and the IHC results, were blinded before data processing. In addition, we collected the IHC profile data of 164 TUOs for test dataset diagnosed in 2020 from the archives at Uijeongbu St. Mary’s Hospital, College of Medicine, The Catholic University of Korea. TUOs were defined as the cases in clinical or pathological situation, where the immunohistochemical differential diagnosis is needed to differentiate between primary or metastatic lesions, or between variable subtypes of cancers, for confirmative diagnosis. In such cases, the histological findings alone cannot exclude the possibility of misdiagnosis or misclassification (e.g. determination of tumour origin in ascites, pleural fluid, or lymph nodes; determination of primary or metastatic lesions and pathologic subtyping in the needle biopsy samples of lung, liver, or kidney, where metastasis is common and clinicoradiologic findings are not confirmative). For training and validation, the retrieved database was divided into 6:4. The cases with inadequate IHC profiles such as the absence of markers for tumour origins, IHC less than three antibodies, inconclusive results were excluded. However, only prognostic markers such as EGFR or p53 were eliminated. Supplementary Fig. 2 showed an example of retrieved IHC profile dataset from patients. The precision of diagnosis presumption algorithm was confirmed by the inclusion of the diagnosis obtained by conventional methods in the top 10 presumptive diagnoses generated by the algorithm. It is considered to be inclusive, without significant difference in the IHC profile, between the initial and presumptive diagnosis, but the only difference in location (e.g., gastrointestinal stromal tumour of the stomach vs. small intestine). The hit rate of training and validation data was compared to prove the functionality of the algorithm. The algorithm is considered validated, if there is no statistically significant difference between the training and validation dataset. After training and validation, algorithm was tested with dataset of another institute (external validation).
Statistical Analysis
Time and computer complexity were accessed by testing the mobile application. Chi-square test was used to compare the hit rate between original and presumptive diagnoses. A web-based statistical analysis (“http://web-r.org”) was used for statistical analysis.
{kind=link}
{kind=link}