Assessment in medical education should ensure doctors are competent, safe practitioners (1, 2). Typically, candidates approaching registration must sit an “exit” assessment to confirm suitability to work as a doctor (3). The reliability and validity of such assessments are of great importance in maintaining the quality of medical education and ensuring patient safety.
Evaluating such assessments can be difficult. In almost all regulatory environments doctors graduate from different institutions. Therefore, a range of institutional contexts, curricula, admissions policies, and resources produce doctors who are nominally equivalent, but differ in experiences (4). Regulators seek to ensure equivalence across institutions by monitoring and enforcing a shared set of values and requirements (5).
As the content, structure, and weighting of exit assessments vary, direct comparisons across institutions are very difficult to carry out. Several partial solutions have been tested. One approach is to compare candidates on later – usually postgraduate – assessment which can act as a comparative measure. Research has shown that graduates of different medical schools exhibit large differences in performance on postgraduate assessments (6). Relatedly, evidence has suggested that the performance of individual medical students and doctors exhibits at least moderate stability over time (7, 8) which suggests the type of candidates applying to medical schools, or their experiences at medical schools, may create meaningful differences between cohorts upon graduation. Importantly, performance on postgraduate assessment predicts not just technical skill, but professionalism – including the likelihood of being sanctioned while working as a doctor (9).
This research necessarily contains limitations. Postgraduate attainment can only measure capabilities some years after doctors begin work and cannot confidently identify the source of such differences. Postgraduate assessments are often specialised and sat by only a subset of doctors, and candidates who exit the profession soon after graduation will never sit them.
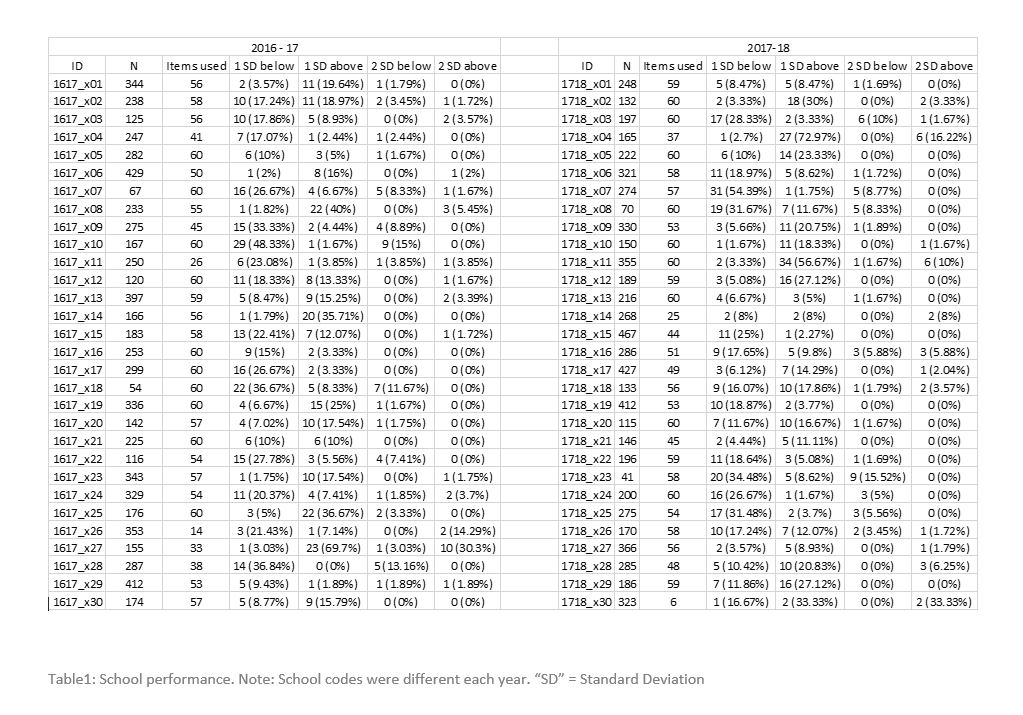
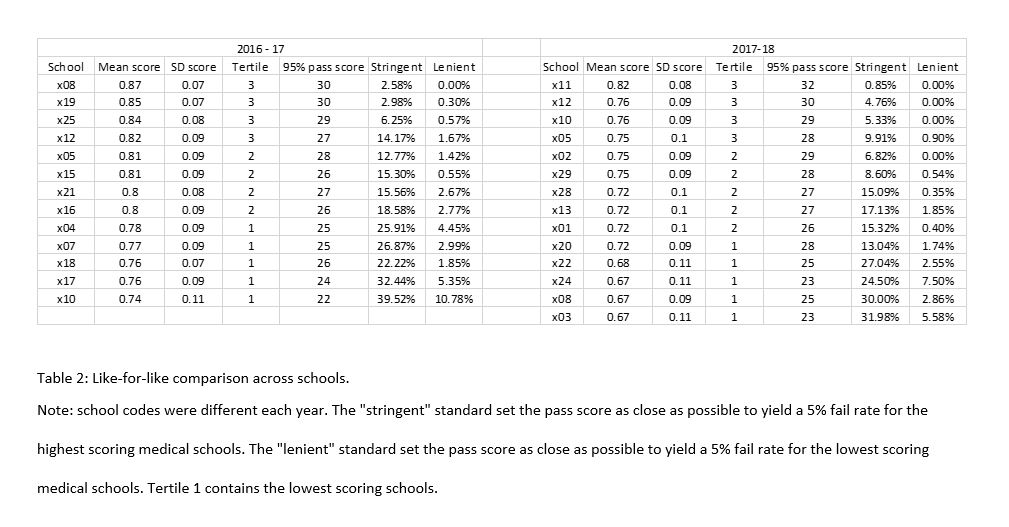
An alternative method lies in the use of “common content.” Here, a group of institutions pool resources and share assessment content across institutions. So, a group of medical schools may share stations in a clinical examination, or multiple-choice questions (MCQs) in a written examination, with the remaining content set locally and independently. By evaluating both the approach to standard setting and the attainment of different cohorts, it is possible to get a better sense of how variable institutions within a regulatory framework are. Research on common content has suggested that different medical schools set very different standards for identical content. Research on MCQ-type written assessment has shown significant differences in medical school standard setting with typically medium effects, with the attendant risk that candidates who passed at institutions with lenient standards would have failed – and therefore not graduated – at institutions with more stringent standards for the same content (10). A follow-up exploration of standard setting at some of the same schools described institutional, individual, and group factors combining to create highly unique standard setting procedures despite using the same content at all institutions (11).
Research on “common content” clinical examination stations have found similar problems, with standards for the same station varying by up to 13% between the most lenient and stringent school (3). Evidence on attainment, rather than standards, remains very sparse but some research on clinical examinations showed medical school cohorts scoring significantly differently on common content stations, in a pool of four medical schools (12).
This is extremely important as it suggests that, even if the content tested in different medical schools is equivalent, the local variability of standards may lead to candidates passing in some environments when they would have failed in others. Indeed, research has suggested that across many measures – content, type, duration, and standard setting – medical schools have a widely varying range of approaches (6, 13). The fear that monitoring systems do not ensure comparability across institutions has led to recommendations for a “licensing” assessment which acts as a single point of measurement for all candidates within a regulatory framework (14). The utility of this proposal remains contested. To some it represents the advance of a test-centric culture where learning is devalued (15) and educational diversity reduced (16). To others, there are potentially significant benefits to patient safety by harmonising standards (14, 17).
The practical and theoretical challenges of implementing any multi-site assessment is significant. In the Netherlands, a progress test delivered across institutions has led to a more effective use of resources and enabled cross-school research, but also disagreements over item quality and logistical difficulties in organising the new assessment (18, 19). In the United States, students have responded to the United States Medical Licensing Examination (USMLE) Step 1 with a range of effective self-directed learning behaviours to maximise the likelihood of passing (20). However, the focus on the candidate’s USMLE score has led authors to claim other aspects of performance – including achievements during medical school – have been under-valued, which has in turn led to reporting changes whereby only the candidate’s pass/fail status is reported (21). Such research demonstrates that cross-school assessment inevitably has serious implications for curriculum design and student learning even in areas which the assessment does not directly assess.
Despite the potentially significant impacts of a new licensing assessment on passing rates at medical schools, little is known about how such assessment might influence standard setting and pass rates. As a first step, medical educators at all affected schools should be aware of the relative performance of their students and the potential impact of different standard setting regimes, which can in turn help develop a consensus on how to standard set national licensing assessment in a way that recognises educational diversity while also ensuring patient safety.
To develop better evidence in this area, we used “common content” MCQs developed by the Medical Schools Council Assessment Alliance (MSCAA(10)) to compare candidates at 30 medical schools, evaluate performance differences and estimate the impact of different standards on pass rates ahead of the implementation of a licensing assessment in the United Kingdom.
{kind=link}
{kind=link}