LCA patients
A family with a 5-year-old proband (III-2) and two suspected patients (III-1 and III-3) were recruited for this study. Written informed consent was obtained from each
individual to participate in this study. The proband was diagnosed with LCA at Guangdong
Zhongshan Hospital, Shanghai General Hospital and the Second Affiliated Hospital of
School of Medicine, Zhejiang University. The pedigree was constructed for the proband
based on information provided by the guardians.
DNA isolation and qualification
Total genomic DNA was extracted using the Relax Gene Blood DNA System (Tiangen, Beijing, China) in accordance with the manufacturer’s
instructions. All DNA was dissolved in sterilized double-distilled water and kept
at –20 °C until assayed.
DNA degradation and contamination were monitored on 1% agarose gels. All DNA samples
were examined for protein contamination (as indicated by the A260/A280 ratio) and reagent contamination (indicated by the A260/A230 ratio) with a NanoDrop ND 1000 spectrophotometer (NanoDrop, Wilmington, DE, USA).
Next generation sequencing (NGS)
DNA samples obtained from the proband were sequenced using microarray-based next-generation
sequencing. A custom Sequence Capture 2.1M Human Array from Roche NimbleGen (Madison,
WI, USA) was designed to capture 3093 exons (including 100 bp regions that flanked
each side of the exons) from 222 genes known to be associated with common genetic
diseases, including Retinitis pigmentosa, Waardenburg syndrome, X-linked juvenile
retinoschisis, Crystalline retinitis pigmentosa, Albinism, LCA, Bardet Biedl syndrome
and Cone-rod dystrophy (Table 1). The procedure for the preparation of the libraries was consistent with standard operating protocols published previously [
8].
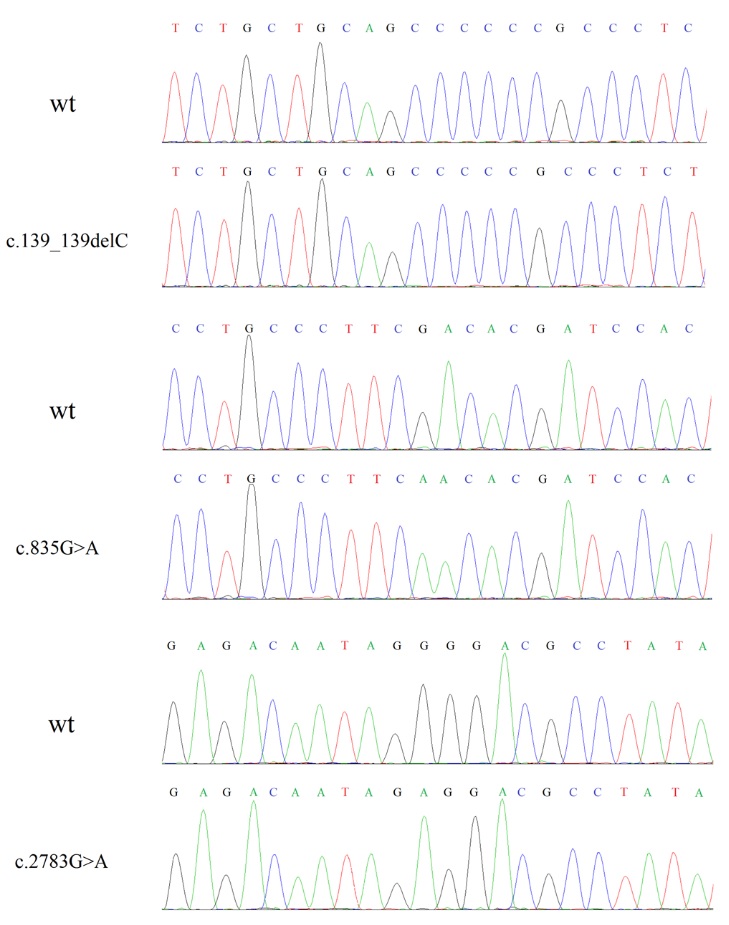
Mutation validation by Sanger sequencing
Candidate variants identified by NGS were validated by Sanger sequencing. Primers
of the GUCY2D gene (NG_009092.1) used in Sanger sequencing were designed by Primer-BLAST (http://www.ncbi.nlm.nih.gov/tools/ primer-blast/), and synthesized by Sangon Biotech (Shanghai, China) (Table 2). All
the amplifications were examined by electrophoresis using 2% agarose gels and sequenced
by BioSune Biotechnology Co., Ltd. (Shanghai, China). The sequencing results were
further compared and analyzed by Mutation Surveyor [
9].
Construction of wt and mutant human ROS-GC1 recombination plasmids
The cDNA of human ROS-GC1 was obtained from Gene Copoeia (EX-Z0715-M98). Primers F
and R contain XhoI and AgeI were used to amplify ROS-GC1 (Table 3). Vector pEGFP-N1
was cutted by XhoI and AgeI. PCR amplify production was sub-cloned into pEGFP-N1 using
ClonExpress (Vazyme, C13) to construct recombined plasmid pEGFP-GC1.
Site-directed mutagenesis PCR was used to construct the mutant ROS-GC1. Primers used
in site-directed mutagenesis PCR are shown in Table 3. Each mutant was achieved by
two step PCRs using pEGFP-GC1 as template. For c.139_139delC (Ala49Profs*36), two
pairs primers F and r-139, R-BamHI and f-139 were used in the first step PCR. F and
R-BamHI were used in the second step. For c.835G>A (Asp279Asn), two pairs primers
F and r-835, R-BamHI and f-835 were used in the first step PCR. F and R-BamHI were
used in the second step. For c.2783G>A (Gly928Glu), primers F-BamHI and r-2783, R
and f-2783 were used in the first step PCR. F-BamHI and R were used in the second
step. For each mutation, amplification products in the first step were cleaned up
(Axygen), mixed, and used as template in the second PCR reaction. All the final PCR
amplification were inserted into the digested pEGFP-N1 using ClonExpress.
Recombined plasmids pEGFP-GC1, pEGFP-Ala49Profs*36, pEGFP-Asp279Asn and pEGFP-Gly928Glu
were transformed into E.coil DH5a. DNA was prepared by using plasmid DNA purification kit from Macherey-nagel following the manufacturer’s instructions. Sequence was verified by Sanger sequencing.
Cellular localization of wt and mutant ROS-GC1 recombination plasmids
pEGFP-N1, pEGFP-GC1, pEGFP-Ala49Profs*36, pEGFP-Asp279Asn and pEGFP-Gly928Glu were
transfected into HeLa cells using transfection reagent PolyJet Reagent (SigmaGen).
After 36h, cells were washed and fixed in 4% paraformaldehyde. The antibody anti-Na+/K+-ATPase (1:100, HuaAn Biotechnology Co.,Ltd) was used to identify the plasma membrane of
HeLa cells. Cell nuclei were stained by 4',6-diamidino-2-phenylindole (DAPI, 10μg/ml,
Solarbio). The detail operational process was performed as described before [
10]. Localization of pEGFP-N1, pEGFP-GC1, pEGFP-Ala49Profs*36, pEGFP-Asp279Asn and pEGFP-Gly928Glu
in HeLa cells were observed by Nikon A1R.
Validation of cGMP quantitation by HPLC-MS/MS
HeLa cells were transfected with pEGFP-N1, pEGFP-GC1, pEGFP-Asp279Asn and pEGFP-Gly928Glu.
After 36h, cells were collected from 100mm plates and washed three times with PBS.
Removed the supernatant carefully, added 300l of ice-cold extraction medium (acetonitrile/methanol/water, 2/2/1 v/v/v) to each
tube. 25ng/ml tenofovir (TNF) was added as internal standard. After dissolving, the
sample was frozen in liquid nitrogen for 30s immediately to stop cGMP metabolism,
followed by incubating in a 37°C water bath for 60s. After repeating 6 times, samples
were heated at 98°C for 20min. Samples were cooled down on ice and centrifuged at
20,000×g 4°C for 10min. The supernatant was transferred into a new tube and the unsolved
residue was extracted two more times with 400μl extraction medium. After evaporating,
we collected the residues and dissolved it in water for further analyze.
The cGMP concentrations were analyzed via HPLC-MS/MS. The samples were applied to
HPLC utilizing ACQUITY CSH-C18 column (1.7μm, 2.1×100mm column, Waters, Ireland). The binary pump system supplied two eluents for chromatographic
analysis, eluent A (10mM formic acid) and eluent B (acetonitrile). Flow rate was 0.3ml/min.
Analyte detection was conducted on the sensitive triple quadrupole mass spectrometer
(Waters TQ-XS, USA). Nitrogen was used as collision gas. 100ng/ml cGMP (G7504, Sigma,
Germany) was used as a standard. All the processes were referenced to method described
before [
11].
Bioinformatics analysis
All the sequences were analyzed by the Mutation Surveyor software and aligned to the
NCBI nucleotide sequence of GUCY2D (NG_009092.1). The pathogenicity of mutations was evaluated using the in silico predictors
SIFT (http://sift.jcvi.org/), PolyPhen-2 (http://genetics.bwh.harvard.edu/pph2/) and Mutation Taster (http://www.mutationtaster.org/). Computational modeling for the mutant ROS-GC1 by Chimera (PDB ID: 1AWL) was used
to study the impact of Gly928Glu on the three-dimensional (3D) structure.
{kind=link}
{kind=link}