Background: Researchers developing prediction models are faced with numerous design choices that may impact model performance. One key decision is how to include patients who are lost to follow-up. In this paper we perform a large-scale empirical evaluation investigating the impact of this decision. In addition, we aim to provide guidelines for how to deal with loss to follow-up.
Methods: We generate a partially synthetic dataset with complete follow-up and simulate loss to follow-up based either on random selection or on selection based on comorbidity. In addition to our synthetic data study we investigate 21 real-world data prediction problems. We compare four simple strategies for developing models when using a cohort design that encounters loss to follow-up. Three strategies employ a binary classifier with data that: i) include all patients (including those lost to follow-up), ii) exclude all patients lost to follow-up or iii) only exclude patients lost to follow-up who do not have the outcome before being lost to follow-up. The fourth strategy uses a survival model with data that include all patients. We empirically evaluate the discrimination and calibration performance.
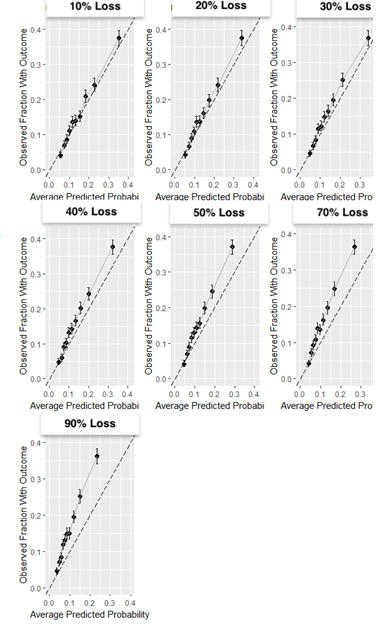
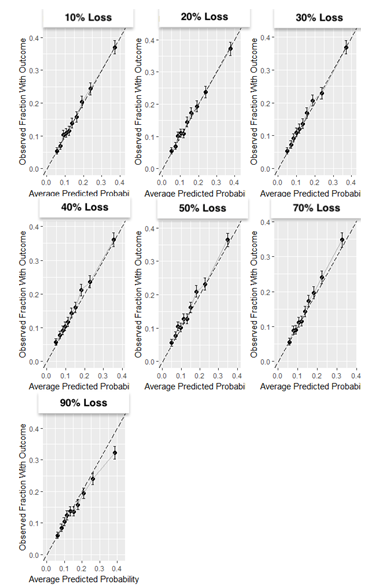
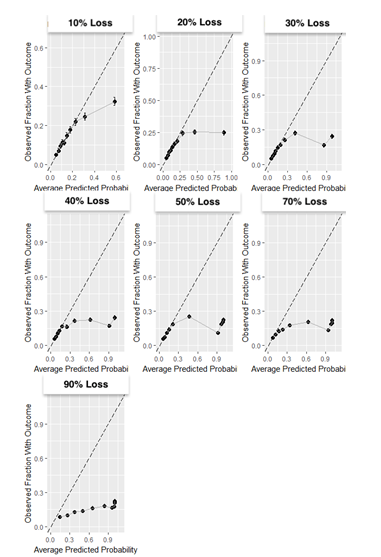
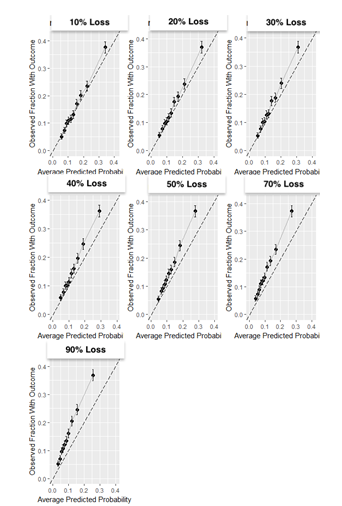
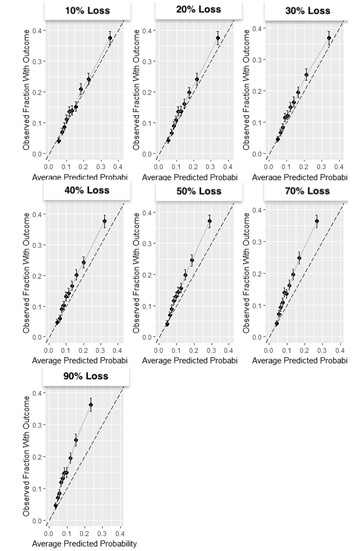
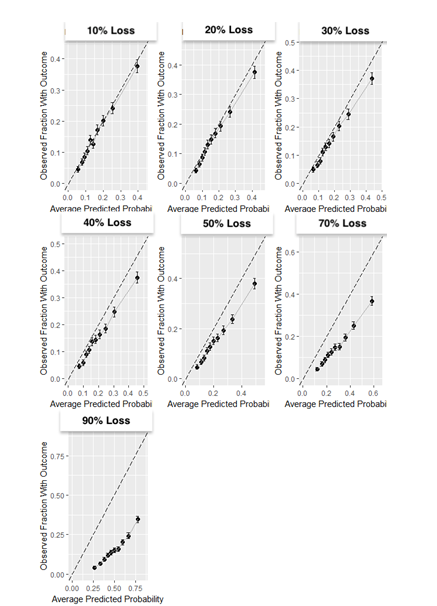
Results: The partially synthetic data study results show that excluding patients who are lost to follow-up can introduce bias when loss to follow-up is common and does not occur at random. However, when loss to follow-up was completely at random, the choice of addressing it had negligible impact on the model performance. Our empirical real-world data results showed that the four design choices investigated to deal with loss to follow-up resulted in comparable performance when the time-at-risk was 1-year, but demonstrated differential bias when we looked into 3-year time-at-risk. Removing patients who are lost to follow-up before experiencing the outcome but keeping patients who are lost to follow-up after the outcome can bias a model and should be avoided.
Conclusion: Based on this study we therefore recommend i) developing models using data that includes patients that are lost to follow-up and ii) evaluate the discrimination and calibration of models twice: on a test set including patients lost to follow-up and a test set excluding patients lost to follow-up.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}